
My live experience at the AI Engineer World’s Fair 2025 in San Francisco could be summarized as “extremely intense.” As I sat down to recap my highlights, starting with this post covering what Day 1, I ended up re-watching every session, and now I understand better why it felt so intense—the amount of information packed into the short 20 minute sessions was immense, and the people communicating that information were, on average, “brilliant plus” humans …
Here’s a quick summary table of what I attended in-person, with links to the detailed sections with my recaps—some brief, some more extended—and links to the session video. I had originally included ratings, but pretty much everything deserved five stars so I canned that idea.
I hope these notes help you get a sense of the energy, trends, and ideas shaping the future of AI and AI Engineering. Enjoy!
Designing AI-Intensive Applications
Speaker: Shawn “swyx” Wang (Latent Space) – Session video
Swyx delivers an incredible overview of the state of the space. He compares today’s state of AI today to early days in physics where the Standard Model was developed and ended up serving physics almost unchanged through today. Swyx proposes a candidate for AI’s own Standard Model, SPADE:

Spark to System: Building the Open Agentic Web
Speaker: Asha Sharma (Microsoft) – Session video
As with AWS’s keynote later in the day featuring Antje Barth, this session with Microsoft’s Asha Sharma set off my “oh no, vendor product-flogging ahead” alarm. That’s not being fair though; we need major players like MS who can deliver necessary, massive-scale platforms, and they need to flog the sexy bits so they can sell the boring ones; no margin, no mission, as they say.
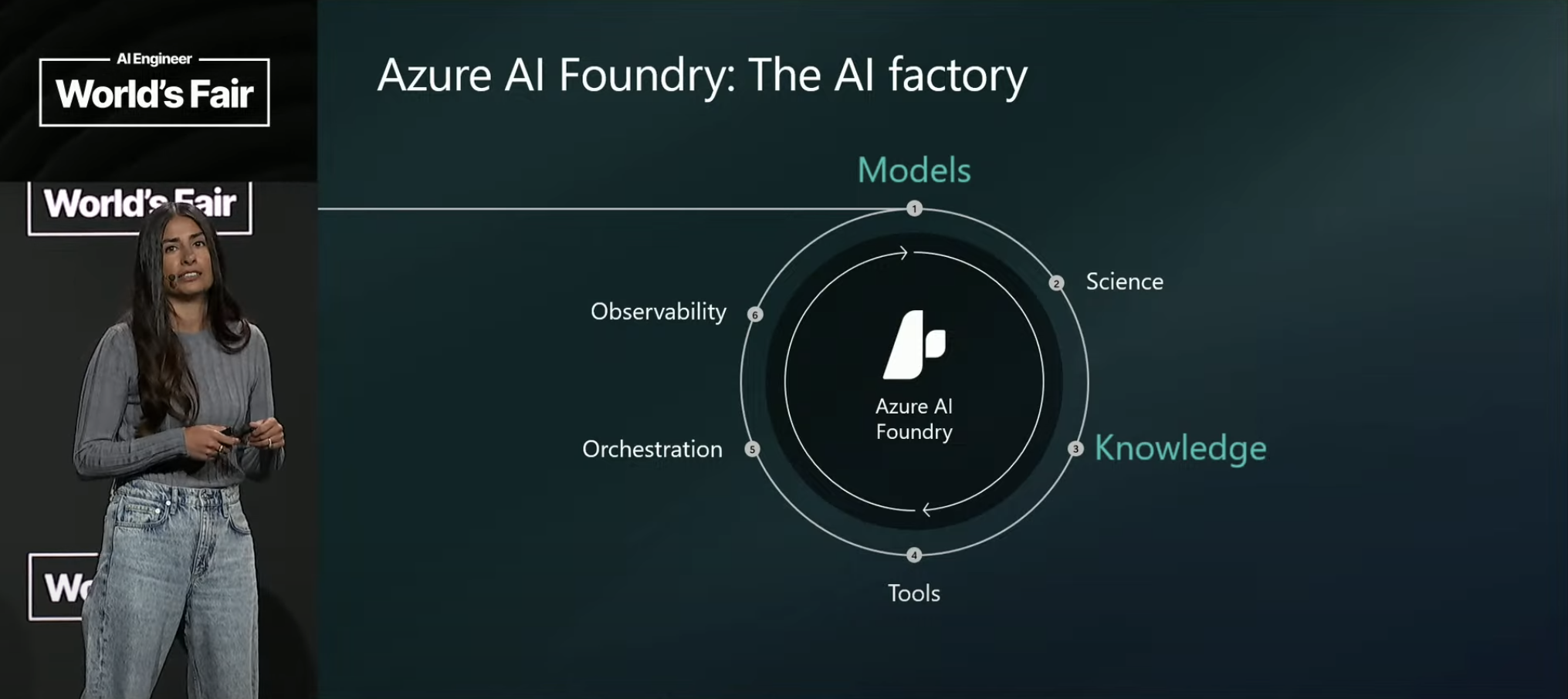
It’s also not fair in that Microsoft has staked out major segments in the AI landscape, even beyond their huge (if now troubled) partnership with OpenAI—Copilot of course, but also the VS Code ecosystem with its pioneering role in AI Coding, GitHub serving as a core source of context for AI Coding and actions in the agentic subcategory, and on and on.
Sharma shows us some significant new capabilities arriving in Copilot, and with her team presents a couple different agentic app solutions. Worth watching, understanding Microsoft’s broad suite of AI offerings is essential.
State of Startups and AI 2025
Speaker: Sarah Guo (Conviction) – Session video
Sarah wins the “best save” award when AV fails, leaving her with no slides … she still pulls off a great presentation, and doesn’t even run over. Excellent overview of the state of AI, the pace of progress, trends. I’m a fan of the Cursor AI Coding tool—one of Conviction’s portfolio companies—and I love Sarah’s recommendation to startups that they should think about building “Cursor for X” … it’s a nuanced message, though: she gets to the heart of what Cursor actually is: an LLM wrapper, yes, but a thick, juicy wrapper.

2025 in LLMs so far
Speaker: Simon Willison (SimonWillison.net) – Session video
I’m a huge fan of Simon’s, and here he’s in fine form—fine enough that this presentation won best-of-conference. As an indicator of the accelerating pace of LLM development, Simon was forced to cut the scope of his keynote from “the past year” to “the past six months” to have a prayer of finishing in the allotted 20 minutes.

His “draw a pelican riding a bicycle” LLM benchmark is both hilarious and an uncannily accurate LLM quality assessment. At least until “the pelican test” starts to contaminate model training—I’m betting next year this benchmark may no longer yield valid results after Willison showed the Google Gemini 2.5 Pro pelican on a Google slide from the recent Google IO event …

MCP Origins & Request for Startups
Speaker: Theo Chu (Anthropic) – Session video
Great intro to Model Context Protocol (MCP), an open standard invented by Anthropic—I love authoritative sources. Origins and futures. Highly recommended, start here on MCP.

What we learned from shipping remote MCP support at Anthropic
Speaker: John Welsh (Anthropic) – Session video
This session got straight to the heart of my most important questions about MCP. Even more background on MCP origins, vital information on the elements of MCP. Love the “pit of success” concept—make the right thing to do, the easiest thing to do. Excellent.

Full Spectrum MCP: Uncovering Hidden Servers and Clients Capabilities
Speaker: Harald Kirschner (VS Code, Microsoft) – Session video
Now we have authoritative from Microsoft: Harald Kirschner, a Principal Product Manager working on VS Code and GitHub Copilot, who was instrumental in releasing Agent Mode in Copilot. Kirschner dives a layer deeper into MCP, with great insights into how “early days” we are, and the basic primitives of the protocol. He does a great job of explaining the self-reinforcing trap that MCP finds itself in at this early stage, where both MCP servers and clients all tend to support the tools primitive, but most lack support (especially thoughtful support) of more powerful primitives such as resources and sampling that enable what he calls “rich, stateful interactions.” And guess what he announced for VS Code: full MCP spec support.

MCP isn’t good, yet
Speaker: David Cramer (Sentry) – Session video
I immediately liked Cramer and his common-sense, from-the-trenches perspective on MCP. Loved his “hot takes” imagery—he described the current phenomenon with MCP where there are lots of “I have opinions but haven’t actually built anything” people hanging around. Sentry wasn’t the earliest MCP adopter; what held them back was that they needed a Remote MCP solution with OAuth, which is only recently becoming viable. He warns about the many problems inherent with stdio and recommends to not screw around with it, just do OAuth, even internally—it will be worth the effort.

The Sentry MCP is a really a great example of “yet another bit of context” for the IDE, and their thoughtful approach instructive. Cramer reinforced the message that we can’t just wrap our APIs as MCP tools, with the same endpoints and the same payloads. “MCP is not just a thing that sits on top of OpenAPI …” Why? “Robots don’t know how to reason about giant JSON payloads that were not built for them .. we can’t just expose all those things as tools …” He makes it clear that we “need to really think about how would you use an agent today, how would the models react to what you do when you provide them context which is what this really is for, and design a system around that … it might leverage your but it is not your API.” In terms of what tools should return, he explains that, in practice JSON is the wrong answer, because language models don’t actually handle “unexpected JSON” well: “It can kinda figure out JSON here and there but if you actually push it you’ll find it breaks all the time …” What payload format to return then? Instead of JSON, they ended up using Markdown. They expose some of the API endpoints, and return some of API’s response as Markdown: “The bare essentials, in a structured way, that a human can think about—because if a human can reason about it, the language model can reason about it …”

Other great tips. “Mind your tokens …” because the user is paying for them. Or even spend some tokens yourself, by exposing agents (Sentry’s “Seer” for example) instead of dumb tools. Cramer says agentic-loop MCPs don’t work well yet (due to lack of streaming, loop waiting delays, etc.) but the promise is real and when it arrives the value will be super high. “This stuff is not that hard … you can just go build it and try it out …” “Everybody is scared of all this stuff because there’s fancy new words for everything … but those fancy new words for things we already have, a new coat of paint—MCP is just a plug-in architecture, agents are just services, LLM calls and MCP calls are just API calls with a new response format, etc.”

Cloudflare usage was really interesting: “We used a lot of Cloudflare tech … shim up a thing on Workers, they have an OAuth proxy …” explaining “we didn’t have websocket infrastructure internally, but the MCP protocol requires it … problem solved …” Super valuable session.
MCP is all you need
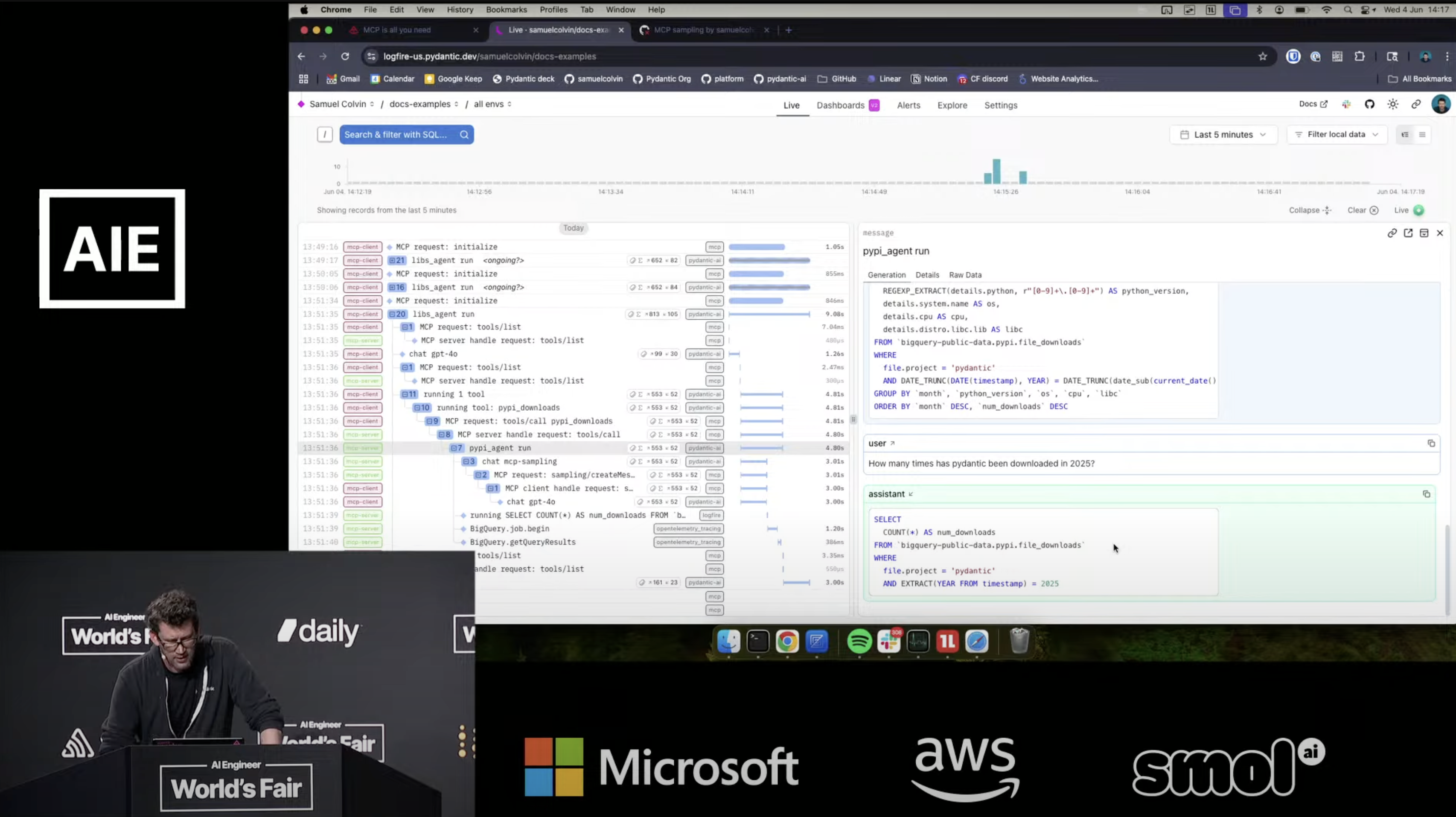
Speaker: Samuel Colvin (Pydantic) – Session video
Colvin and Pydantic are famous for the Pydantic Python package, which had been downloaded 1.6B times so far this year, as of the date of the talk.
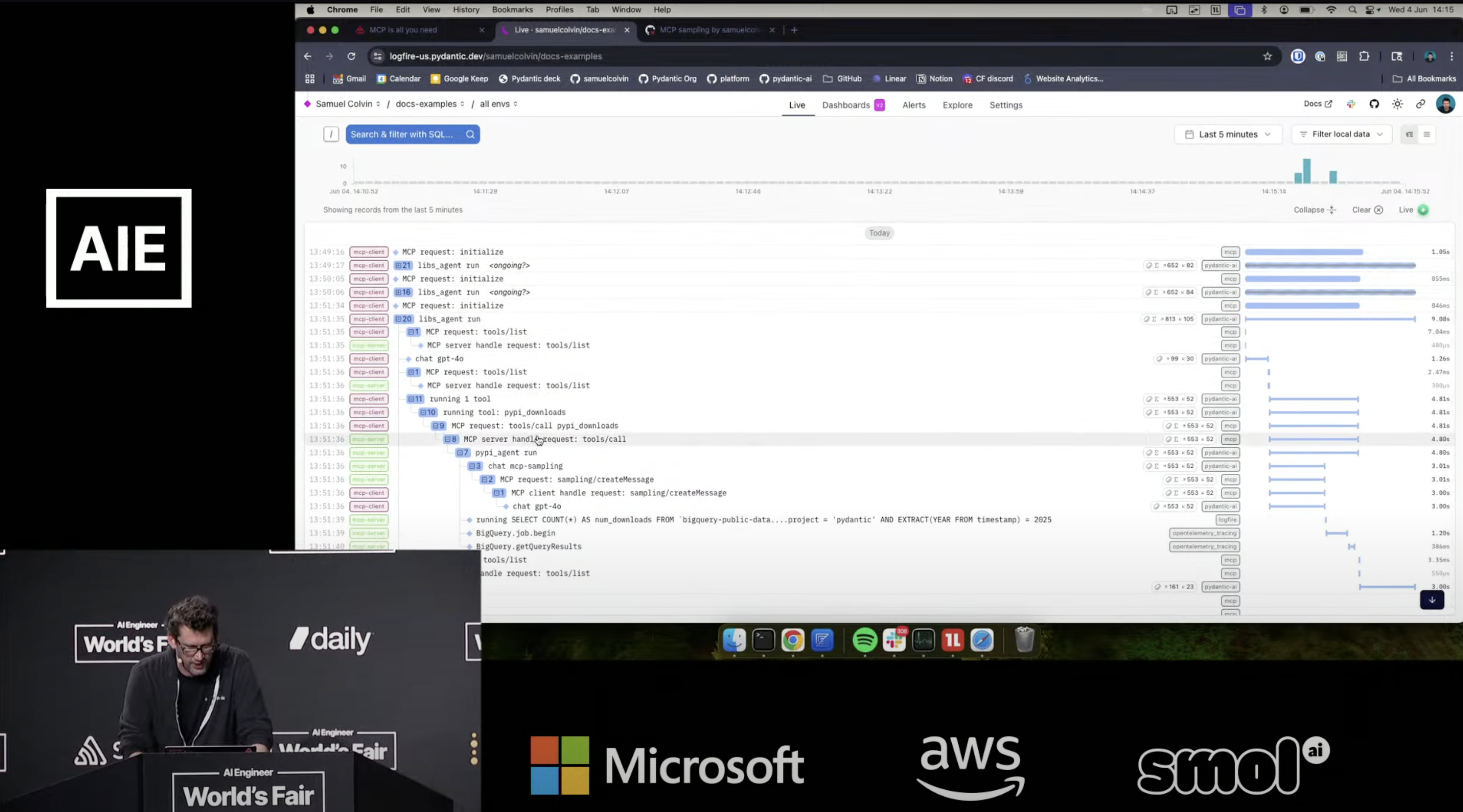
The title “MCP is all you need” plays off Jason Liu’s “Pydantic is all you need” talk from about two years ago, and follow-on talk from about a year ago, “Pydantic is still all you need.” Both talks have the same theme: you’re overcomplicating things, people! Colvin goes on to show is just how powerful MCP can be, in conjunction with Pydantic’s (also free open source) Pydantic AI package, along with Pydantic Logfire, their paid observability platform based on the OpenTelemetry standard. Colvin walks through all the code, and runs it, right there during his 20-minute talk, despite Wi-Fi troubles. Colvin explains why MCP’s tool calling capabilities are much more complex and powerful than you might at first imagine—dynamic tools, logging, sampling, etc. His explanation of the poorly-named and frequently-misunderstood sampling element of the MCP protocol is excellent—he makes clear exactly why sampling is so useful and critical.
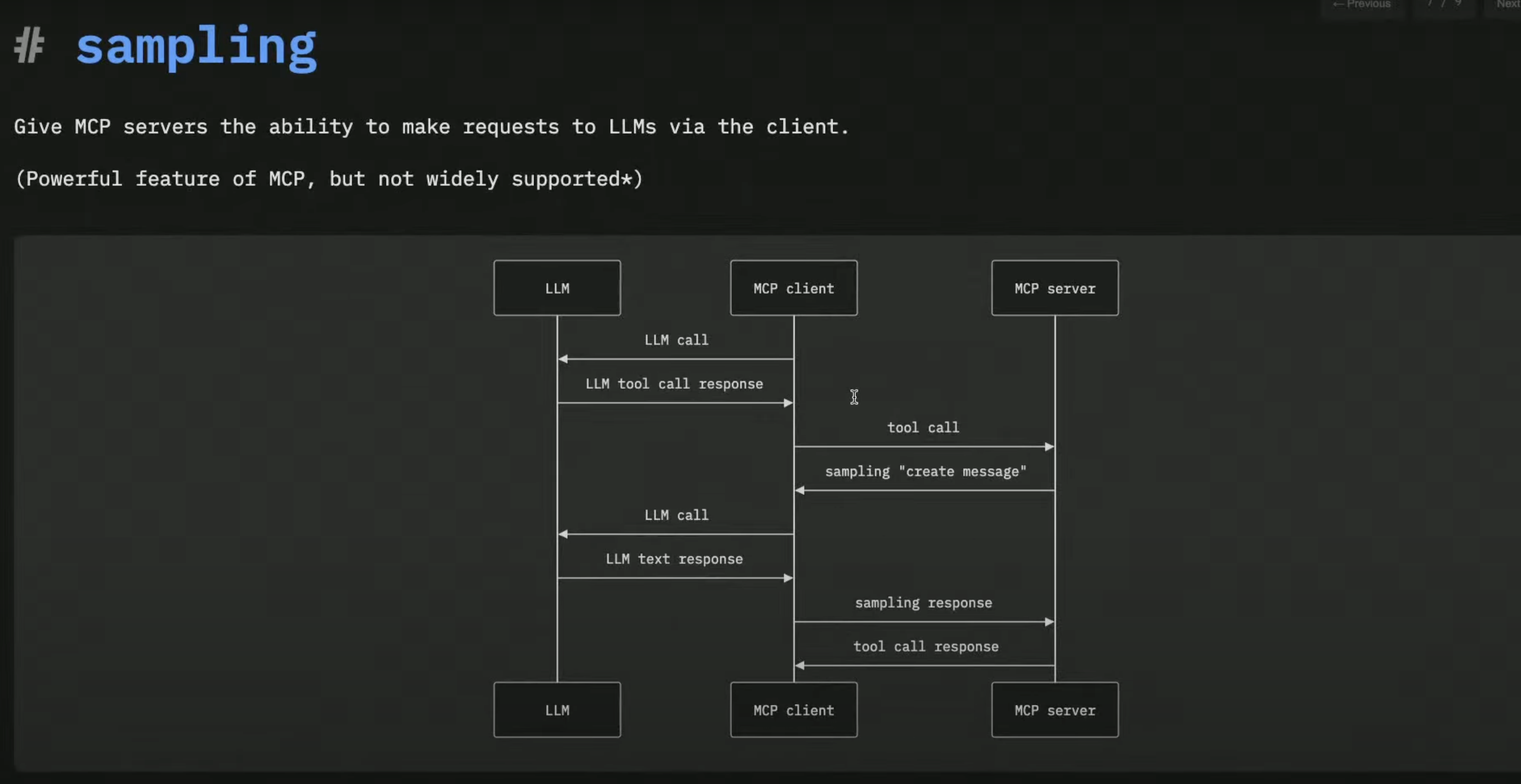
The power of well-implemented observability within an MCP server is clearly on display, delivered via Logfire, which has landed on my go-to list for observability.
Observable tools - the state of MCP observability
Speakers: Alex Volkov (Weights & Biases), Benjamin Eckel (Dylibso) – Session video
This session took me deeper into the details of MCP observability than I needed to go—I need to know what’s possible, and where to find the details when I need them, but not the full details right now when I don’t yet need them. For someone in the midst of building a robust MCP for production use, though, I’m sure this content would be super useful.
Alex Volkov’s Weights & Biases is known for their observability tool Weave. Benjamin Eckel operates MCP.run, which consists of a registry of MCPs, along with tools to glue together, orchestrate and run MCPs (AI services). Both feel the pain of the MCP observability blind spot (black boxes).

Both recommend a standards-based approach: leverage OpenTelemetry (OTel) within MCPs as the best approach for making the MCP black box observable. They explain core concepts of OTel—traces, spans, sinks, etc. Both show code solutions on their respective platforms applying OTel. Volkov also shows a great example of MCP in action in Windsurf, relating to debugging code via MCP tracing.

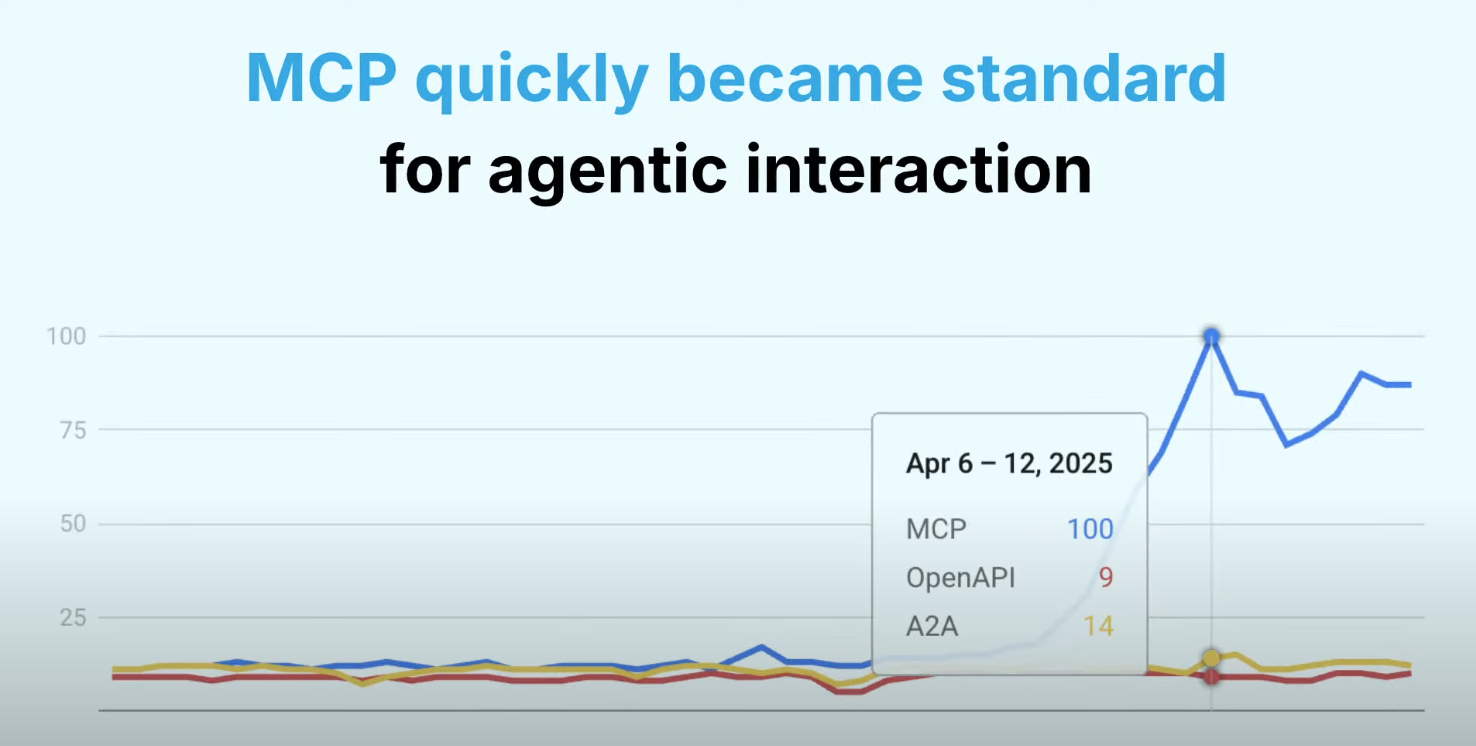
The rise of the agentic economy on the shoulders of MCP
Speaker: Jan Čurn (Apify) – Session video
Čurn’s company Apify is a marketplace (read: monetized) of 5,000+ Actors (read agent-like entities), historically web scraping centric, but more recently including other tool categories. Actor creators make money when their Actors are run by Apify customers, with Apify handling payments.infrastructure strong support of standa

MCPs are a slam-dunk addition to the Apify ecosystem. Apify was able to expose all 5,000+ Actors thanks to what Čurn calls the killer feature of MCPs, Tool Discovery. Not many clients support it yet—VS Code and Claude desktop just added support. Čurn explains that, while there’s no way they could publish 5,000+ Actors via OpenAPI due to search challenges, MCP’s Tool Discovery provided an elegant solution. Čurn points out how dominant MCP is becoming for agentic interaction. There are so many MCP registries that Mastra even has a registry of registries. Double meta. He considers Tool Discovery to be a huge differentiator for MCP.
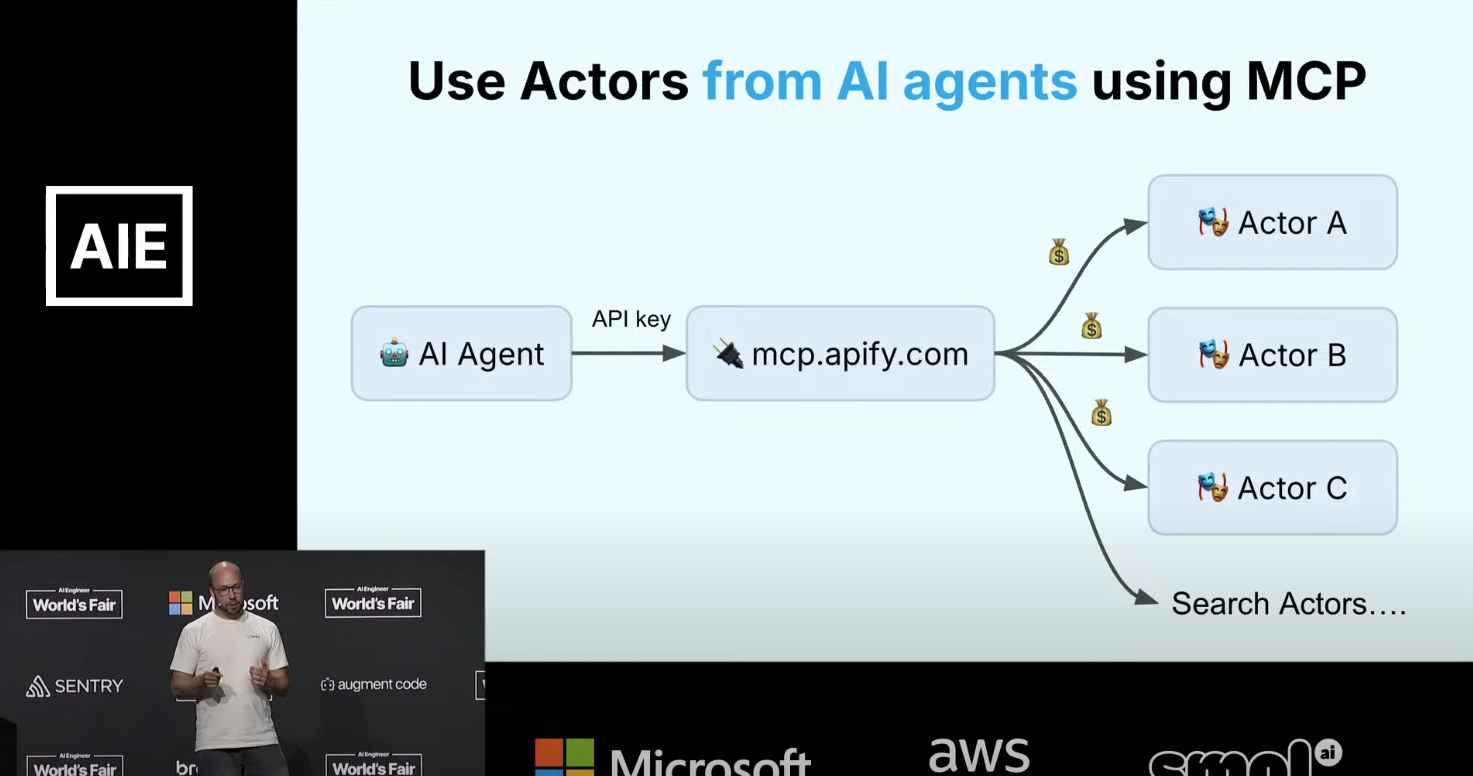
Čurn suggests that, thanks to the richness of the MCP protocol, an agentic economy will arise based on MCP. But: there’s a killer problem: how to handle payments when a group (tree) of paid agents are working together to solve a problem? You might be able to discover other agents, but how would you pay them, each the normal setup is for each service to have its own API key and associated account? Give the parent agent a credit card? Bad for so many reasons. Central identity and payments providers? Maybe someday, but it’s hard and expensive to launch something like that. Apify has a solution: developers just deal with one API key, and interact only with mcp.apify.com; and entire tree of Actors can issue charges, which are passed back up to the dev via Apify. A great demo ensued using Claude Desktop.
Building Agents at Cloud-Scale
Speaker: Antje Barth (AWS) – Session video
As with Microsoft’s keynote featuring Asha Sharma, this session with AWS’s Antje Barth set off my “oh no, vendor flogging ahead” warning lights. That’s not being fair though; we need major players like AWS who can deliver massive-scale platforms, and when you’re AWS or Microsoft, you have to flog the sexy bits so you can sell the boring ones; no margin, no mission, as they say.

It’s also not fair in that, as with Microsoft, Barth and AWS actually had interesting things to show off. Alexa+ sure looks like it brings to the smart home device the level of real-time intelligence and interactivity that OpenAI’s Advanced Voice Mode delivers in their mobile app. I’m cautious, though: Amazon has botched their smart home strategy in the past—see my current Alexa deployment below. My Apple HomePods are likely to join them on the junk shelf as soon as someone trustworthy and with taste delivers on the promise. Apple qualifies as “trustworthy and with taste”—but they continue to foot-gun on AI.

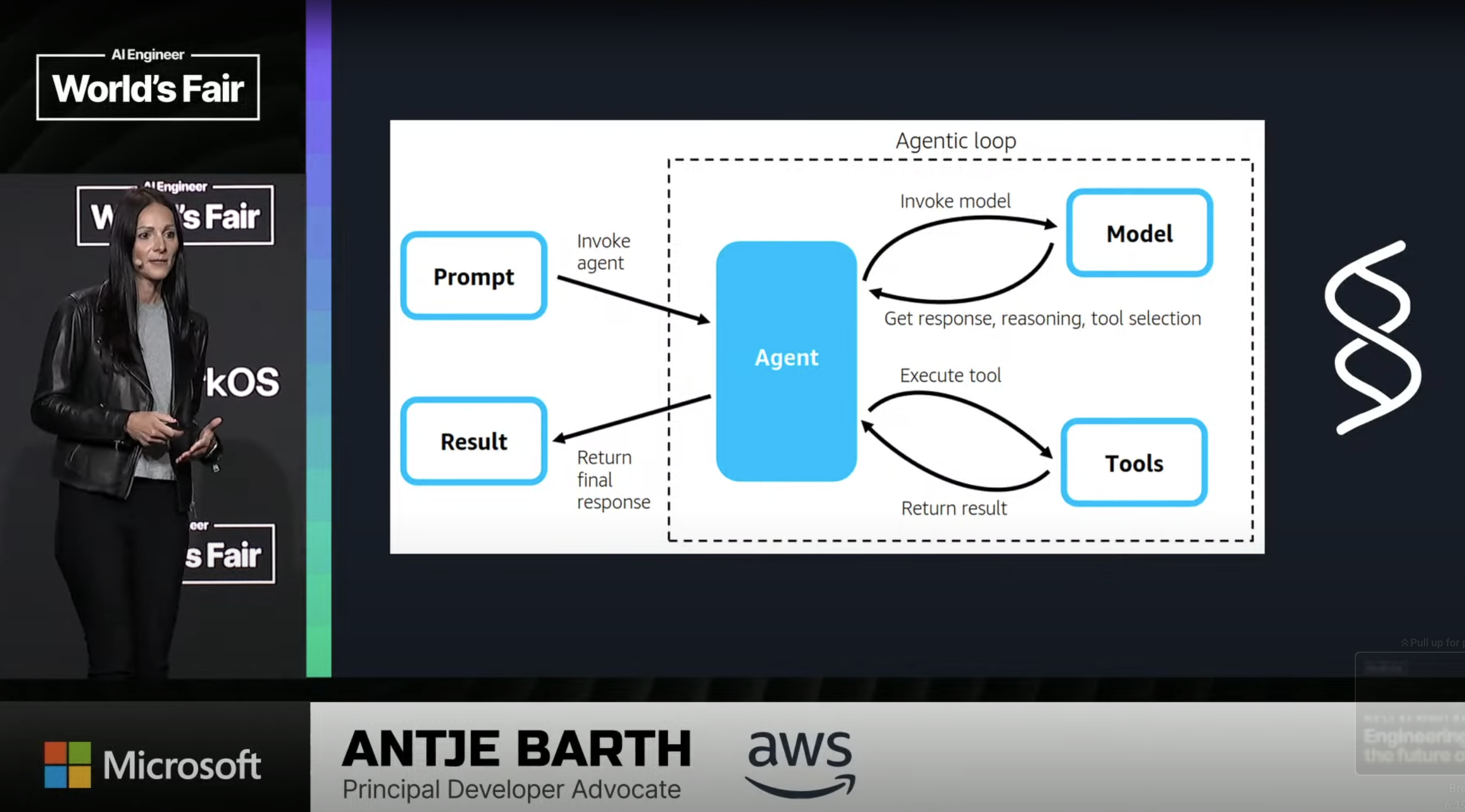
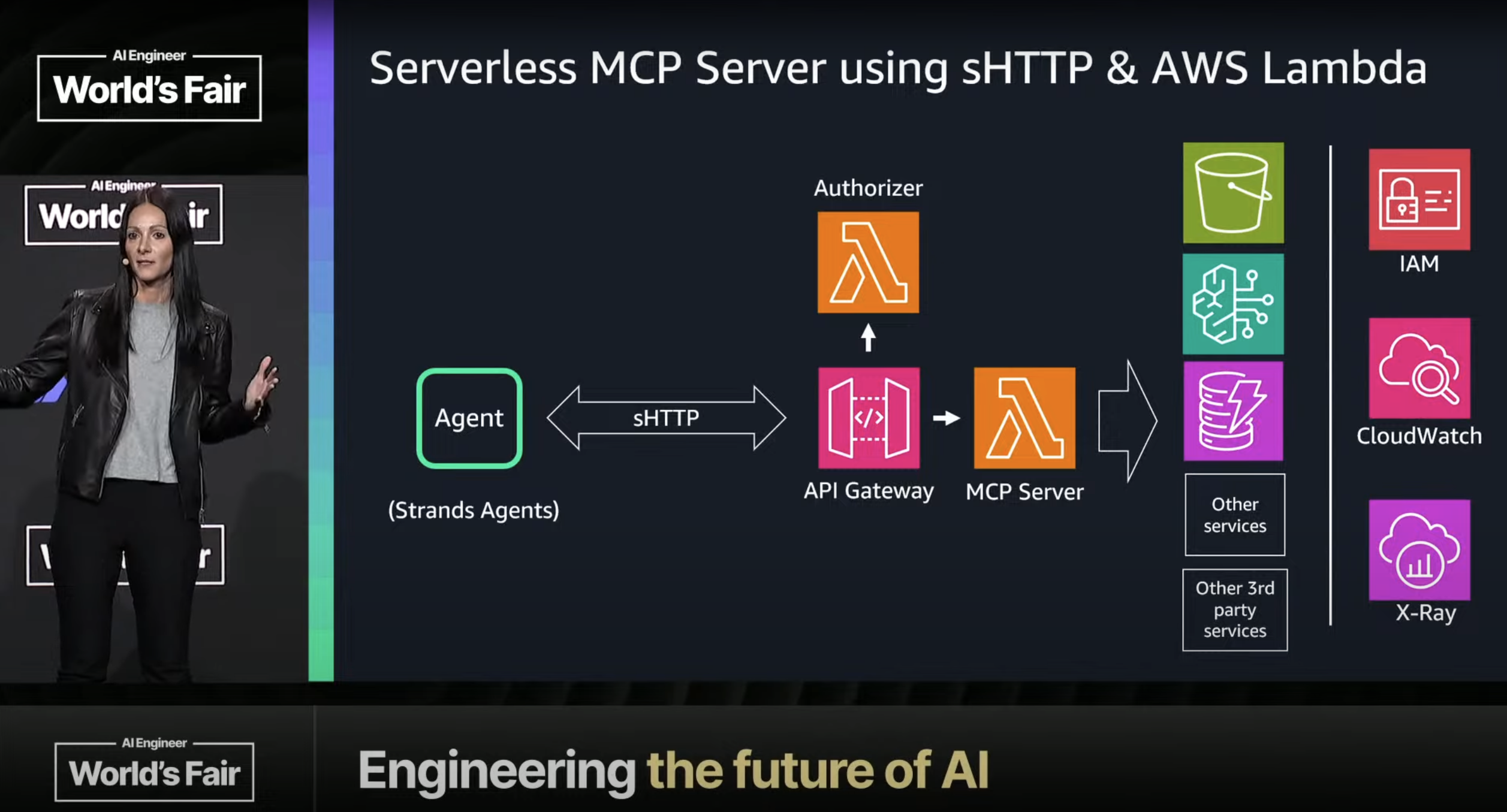
It’s actually interesting how much higher my trust level is for AWS than for mainline Amazon products like Alexa, which leads us to Barth’s main topic, agents at cloud scale. Barth did a quick demo of the AWS Q CLI tool—not impressive on its own, but its three-week time-to-launch was more so. How? AWS Strands Agents (SA). Good things about SA: based over Bedrock, which means a wide selection of models to work with, including Anthropic’s; and a nice starting set of 20 pre-built tools including memory/RAG (the Retrieve tool sounds particularly interesting). What’s less clear is how the SA architecture fits in with MCP; what does SA bring to the table that MCP by itself doesn’t provide? AWS has lots of MCP server implementations, and MCPs can be used as tools within SA; but AWS seem to view MCP as “just one of the open protocols” for agents. We’ll have to wait and see how this plays out.
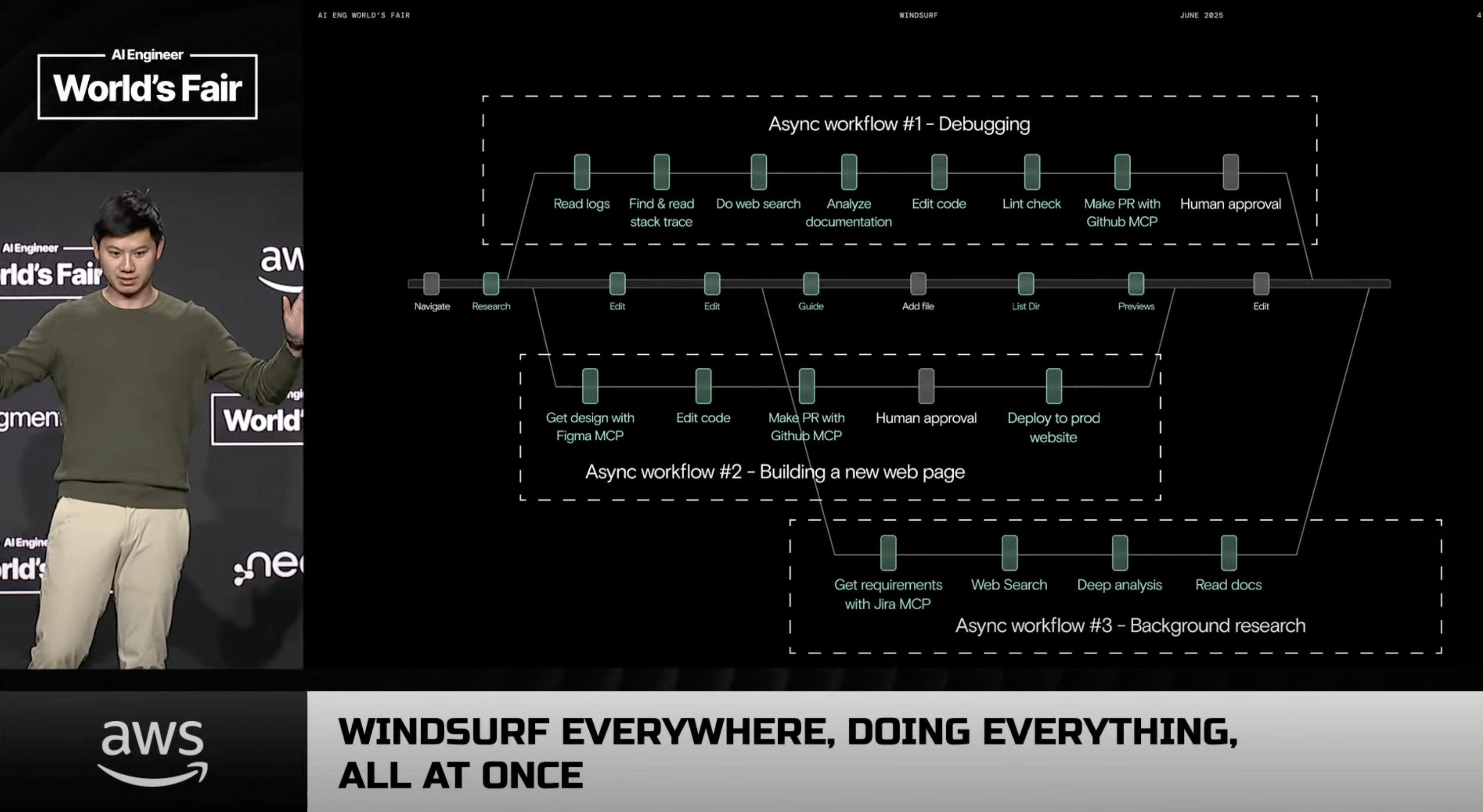
Windsurf everywhere, doing everything, all at once
Speaker: Kevin Hou (Windsurf) – Session video
In the AI Coding space, IDE-tool subspace, my most-admired product, and also the one I have the most experience with, is Cursor. In my experience, which combines a lot of paying attention to what others think and a moderate degree of hands-on use, Cursor leads this sub-niche. The AIEWF2025 audience seemed to agree, when someone asked for raised hands for who uses Windsurf, and who uses Cursor. My estimate was about 5:1 Cursor:Windsurf. Having seen Kevin Hou’s session live, and re-watching it as I write this, I didn’t see anything to change my opinion. Hou claimed he was sharing Windsurf’s “secret sauce”—shared timelines between human and AI—but this and other points made in the sessions struck me as marketing points as opposed to actual breakthroughs. I didn’t see anything new; I just saw obvious points made as if I knew nothing about other tools or the current state-of-the-art in AI Coding.
It’s possible, no doubt, that I’m missing something important. I strive to remain open-minded. I will give Windsurf major credit for capitalizing on OpenAI’s need to beef up their AI Coding story. If Windsurf can close that $3B deal—that fat lady hasn’t sung quite yet—being part of OpenAI may give Windsurf the unique advantage that its current product capabilities do not.
Define AI Engineer
Speakers: Greg Brockman (OpenAI), Shawn “swyx” Wang (Latent Space) – Session video
Swyx conducts a fascinating interview of Brockman, with a little help from Nvidia’s Jensen Huang (prerecorded). Having re-watched as part of writing my recap, I picked up a lot I missed in person. There’s so much content here, and I’ll zoom in on questions in the AI Coding domain.

Swyx: What are your thoughts on vibe coding?
Brockman: I think that vibe coding is amazing as an empowerment mechanism, right? I think it’s sort of a representation of what is to come. And I think that the specifics of what vibe coding is, I think that’s going to change over time, right? I think that you look at even things like Codex like to some extent I think our vision is that as you start to have agents that really work that you can have not just one copy not just 10 copies but you can have a hundred or thousand or 10,000 100 thousand of these things running you’re going to want to treat them much more like a co-worker, right, that you’re going to want them off in the cloud doing stuff being able to hook up to all sorts of things you’re asleep, your laptop’s closed it should still be working. I think that the current conception of of vibe coding in an interactive loop … My prediction of what will happen … there’s going to be more and more of that happening, but I think that the agentic stuff is going to also really intercept and overtake. And I think that all of this is just going to result in just way more systems being built.
Also very interesting is that a lot of the vibe coding kind of demos and and the cool flashy stuff, for example, making the joke website, it’s making an app from scratch. But the thing that I think will really be new and transformative and starting to really happen is being able to transform existing applications to go deeper. So many companies are sitting on legacy codebases and doing migrations and updating libraries and changing your COBOL language to something else is so hard and is actually just not very fun for humans and we’re starting to get AI that are able to really tackle those problems and the thing that I love about where vibe coding started has really been like with the most like just make cool apps kind of thing and it’s starting to become much more like serious software engineering. And I think that going even deeper to just like making it possible to just move so much faster as a company. That’s I think where we’re headed.

Swyx: How do you think that Codex changes the way we code?
Brockman: The direction is something that is like just so compelling and incredible to me. The thing that has been the most interesting to see has been when you realize that the way your structure your codebase determines how much you can get out of Codex, right? Like all of our existing codebases are kind of matched to the strengths of humans. But if you match instead to the strength of models which are sort of very lopsided, right? Models are able to handle way more like diversity of stuff but are not able to sort of necessarily connect deep ideas as much as humans are right now. And so what you kind of want to do is make smaller modules that are well tested that have tests that can be run very quickly and then fill in the details. The model will just do that, right? And it’ll run the test itself.
The connection between these different components, kind of the architecture diagram, that’s actually pretty easy to do, and then it’s like filling out all the details that is often very difficult. And if you actually do that, you know, what I described also sounds a lot like good software engineering practice. But it’s just like sometimes because humans are capable of holding more of this like conceptual abstraction in our head, we just don’t do it – it’s a lot of work to write these tests and to flesh them out and that the model’s going to run these tests like a hundred times or a thousand times more than you will and so it’s going to care way way more. So in some ways the direction we want to go is build our codebases for more junior developers in order to actually get the most out of these models.
Now it’ll be very interesting to see as we increase the model capability, does this particular way of structuring code bases remain constant? I think that it’s a good idea because again, it starts to match what you should be doing for maintainability for humans. But yeah, I think that to me the really exciting thing to think about for the future of software engineering is, what of our practices that we cut corners on, do we actually really need to bring back, in order to get the most out of our systems?

Swyx: Can you ballpark numbers on the amount of productivity you guys are seeing with Codex internally?
Brockman: Yeah I don’t know what the latest numbers are. I mean, there’s definitely a low double digit written entirely by Codex. That’s super cool to see. But it’s also it’s not the only system that we use internally and I think that to me it’s still in the very early days. It’s been exciting to see some of the external metrics. I think we had 24,000 PRs that were merged in like the last day in public GitHub repositories. And so yeah, this stuff is all just getting started.
Jensen Huang: AI native engineers in the audience, they are probably thinking, in the coming years, OpenAI will have AGIs and they will be building domain specific agents on top of the AGIs from OpenAI. So some of the questions that I would have on my mind would be, how do you think their development workflow would change as OpenAI’s AGIs become much more capable and yet they would still have plumbing workflows pipelines that they would create, flywheels that they would create for their domain specific agents. These agents would of course be able to reason, plan, use tools, have memory, short-term, long-term memory, and they’ll be amazing amazing agents, but how does it change the development process in the coming years?

Brockman: Yeah, I think that this is a really fascinating question, right? I think you can find a wide spectrum of very strongly held opinion that is all mutually contradictory. I think my perspective is that first of all, it’s all on the table, right? Maybe we reach a world where it’s just like the AIs are so capable that we all just let them write all the code. Maybe there’s a world where you have like one Al in the sky. Maybe it’s that you actually have a bunch of domain specific agents that require a bunch of of specific work in order to make that happen.
I think the evidence has really been shifting towards this menagerie of different models—I think that’s actually really exciting. There’s different inference costs, there’s different trade-offs like just distillation works so well, there’s actually a lot of power to be had by models that are actually able to use other models. I think that that is going to open up just a ton of opportunity because you know we’re heading to a world where the economy is fundamentally powered by AI. We’re not there yet but you can see it right on the horizon. I mean that’s what people in this room are building – that is what you are doing.
The economy is a very big thing, there’s a lot of diversity in it, and it’s also not static, right? I think when people think about what AI can do for us it’s very easy to only look at what are we doing now, and how does AI slot in, and the percentage of human versus AI, but that’s not the point. The point is how do we get 10x more activity, 10x more economic output, 10x more benefit to everyone. I think the direction we’re heading is one where the models will get much more capable, there’ll be much better fundamental technology, and there’s just going to be way more things we want to do with it and the barrier to entry will be lower than ever. And so things like healthcare that requires responsibility to go in and think about how to do it right. Things like education where there’s multiple stakeholders – the parent, the teacher, the student – each of these requires domain expertise, requires careful thought, requires a lot of work.
So I think that there is going to be so much opportunity for people to build. So l’m just so excited to see everyone in this room because that’s the right kind of energy.