
In my opinion, the two core days of the AI Engineer World’s Fair 2025 in San Francisco represent the ultimate condensation of the state of AI, delivered by many of the the brightest minds in the field. This post covers my Day 2 experience—in case you missed it, here’s my Day 1 recap.
I’m slow publishing this, for which I feel badly, but re-watching thoughtfully 4-8 weeks after seeing the sessions in person has been a tremendous learning exercise for me, and will, I hope, add to the power of my observations.
Here’s a quick table of contents; click to jump to the details.
Gemini 2.5 Pro 06-05 Launch - A Year of Shipping and What Comes Next
Speaker: Logan Kilpatrick (Google DeepMind) – Session video
My level of respect for Google as a model lab has serioiusly lagged Anthropic and OpenAI, but I came away from Logan Kilpatrick’s and Jack Rae’s sessions recognizing how serious a player they are—very strong today with a great pipeline. Google DeepMind officially launched their most powerful model to date, Gemini 2.5 Pro, live at the event. “I think [2.5 Pro] is setting the stage for the future of Gemini. I think 2.5 Pro for us internally and I think in the perception from the developer ecosystem was the turning point which was super exciting. It’s awesome to see the momentum. We’ve got a bunch of other great models coming as well.”

Kilpatrick highlighted a year of Gemini Progress: “It feels like 10 years of of Gemini stuff packed into the last 12 months, which has been awesome”—and talked about how so much Google research is coming together in the new Gemini models: “All of these different research bets across Deep Mind [are] coming together to build this incredible mainline Gemini model. What is the DeepMind strategy? What’s the advantage for us building models? … the interesting thing to me is this breadth of research happening across science and Gemini and robotics and things like that … all that actually ends up upstreaming into the mainline models which is super exciting.”
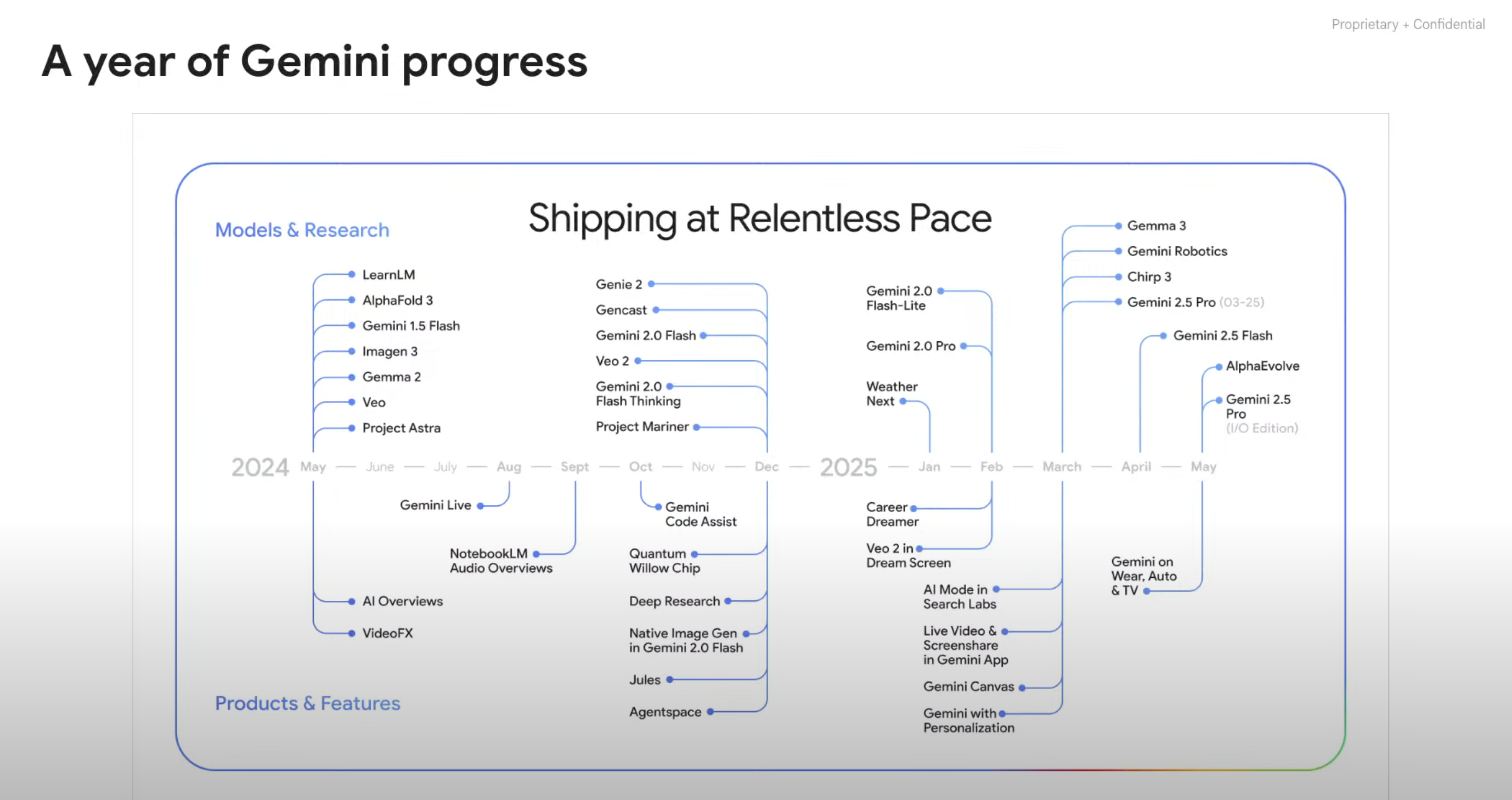
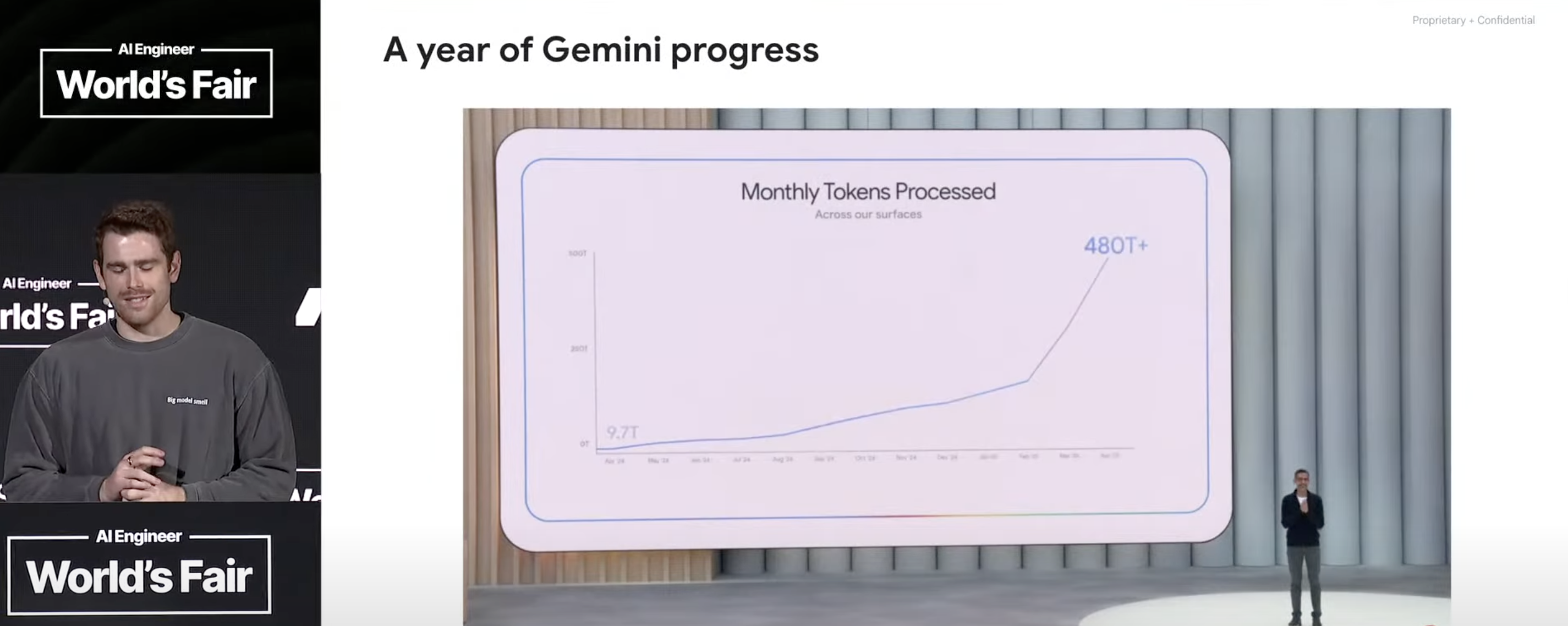
He emphasized it’s “not just the pace of innovation but the pace of adoption … a 50x increase in the amount of AI inference that’s being processed uh through Google servers from one year ago to um last month …” and highlighted the reception to VEO: “It’s burning all the TPUs down.”
Among a number of future themes, he says Google models will be increasingly “agentic by default.” All in all, an impressive story from Google DeepMind.

Thinking Deeper in Gemini
Speaker: Jack Rae (Google DeepMind) – Session video
Google DeepMind’s Jack Rae did a great job taking us back in time to the first language models up to the present day, with emphasis on test-time compute. (Late-breaking news: Rae has left Google to join Meta, likely as part of their new Superintelligence Labs organization.)
Traditional language models are trained to respond immediately to requests, meaning there is a constant, very limited amount of compute applied at test-time. It’s possible to increase TTC by using a larger model, but then all requests are forced to this fixed, larger amount of compute. Not a good scaling approach—much better is to train models that are designed to loop. Loop iteration scale is dynamic, so we can get orders of magnitude more TTC, with control over how hard the model “thinks.” (Later Rae mentions that “thinking budgets” are now part of the API in the Gemini Flash 2.5 and Pro 2.5 models. Developers get fine-grained control over how much TTC gets applied.)
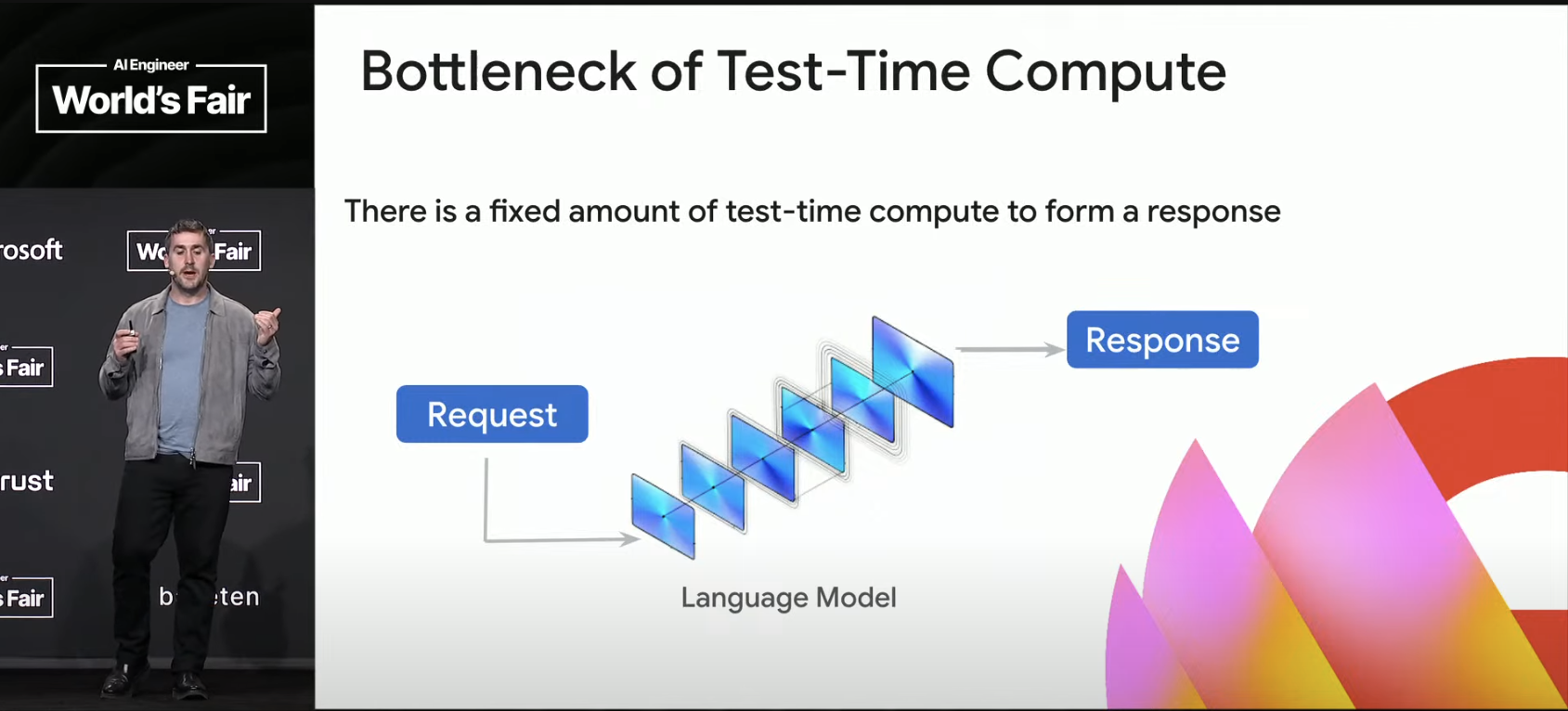
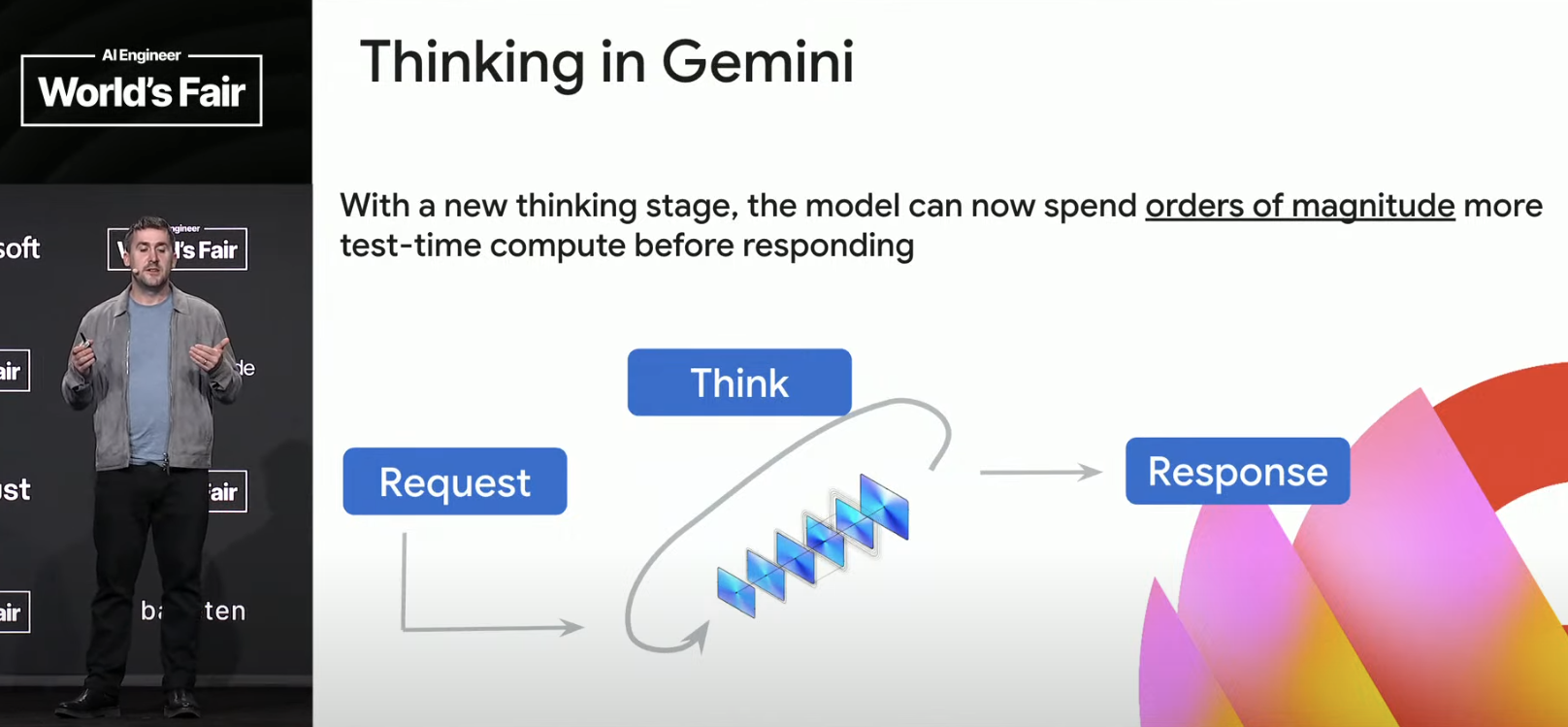
Scaling test-time compute delivers benefits across all model paradigms—there’s a feedback loop effect. If you wonder “how can model (AI) progress keep accelerating?” this is a great example: scaled TTC feeds back to accelerate develeopment of more powerful base models.
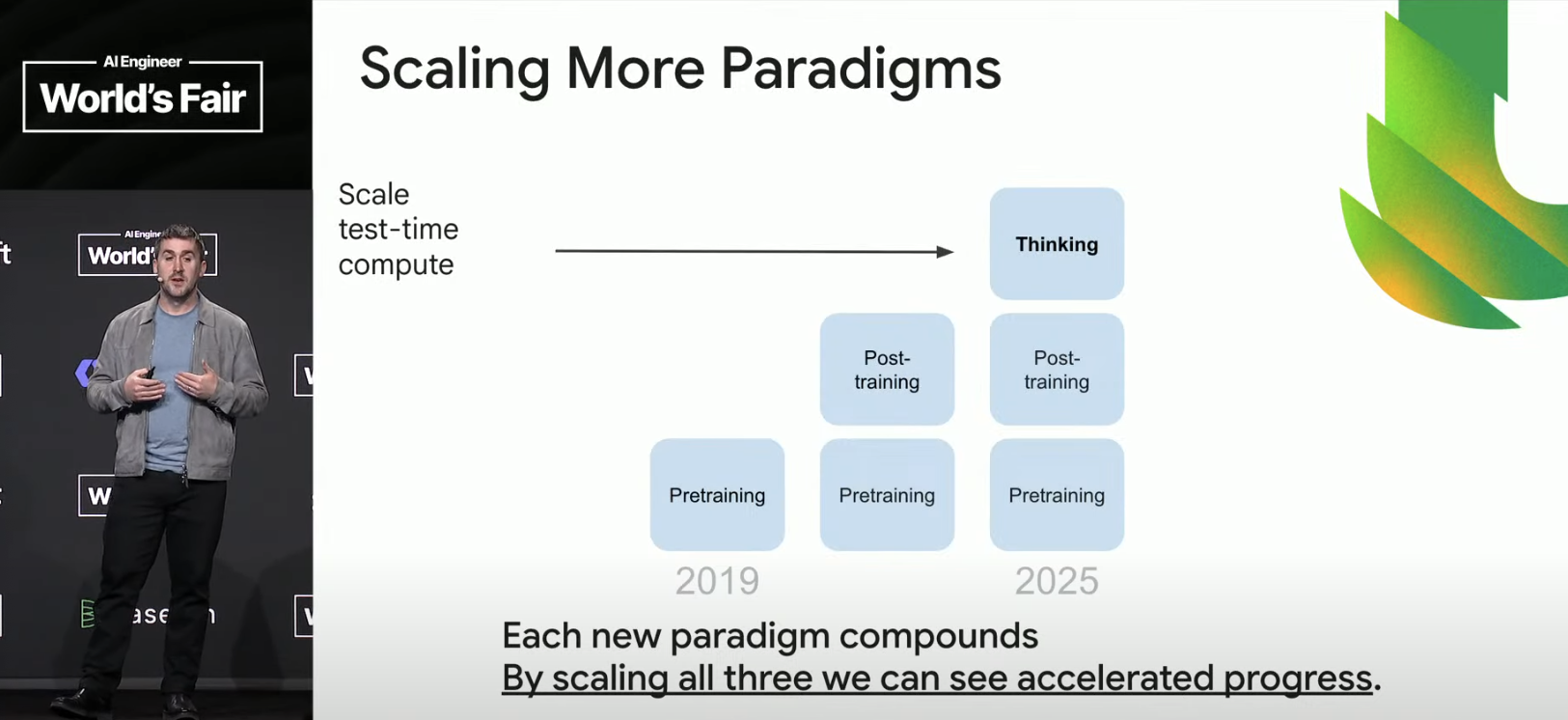
Rae describes the emergent behavior that’s appearing through scaled TTC—effectively, the model learns new thinking strategies.

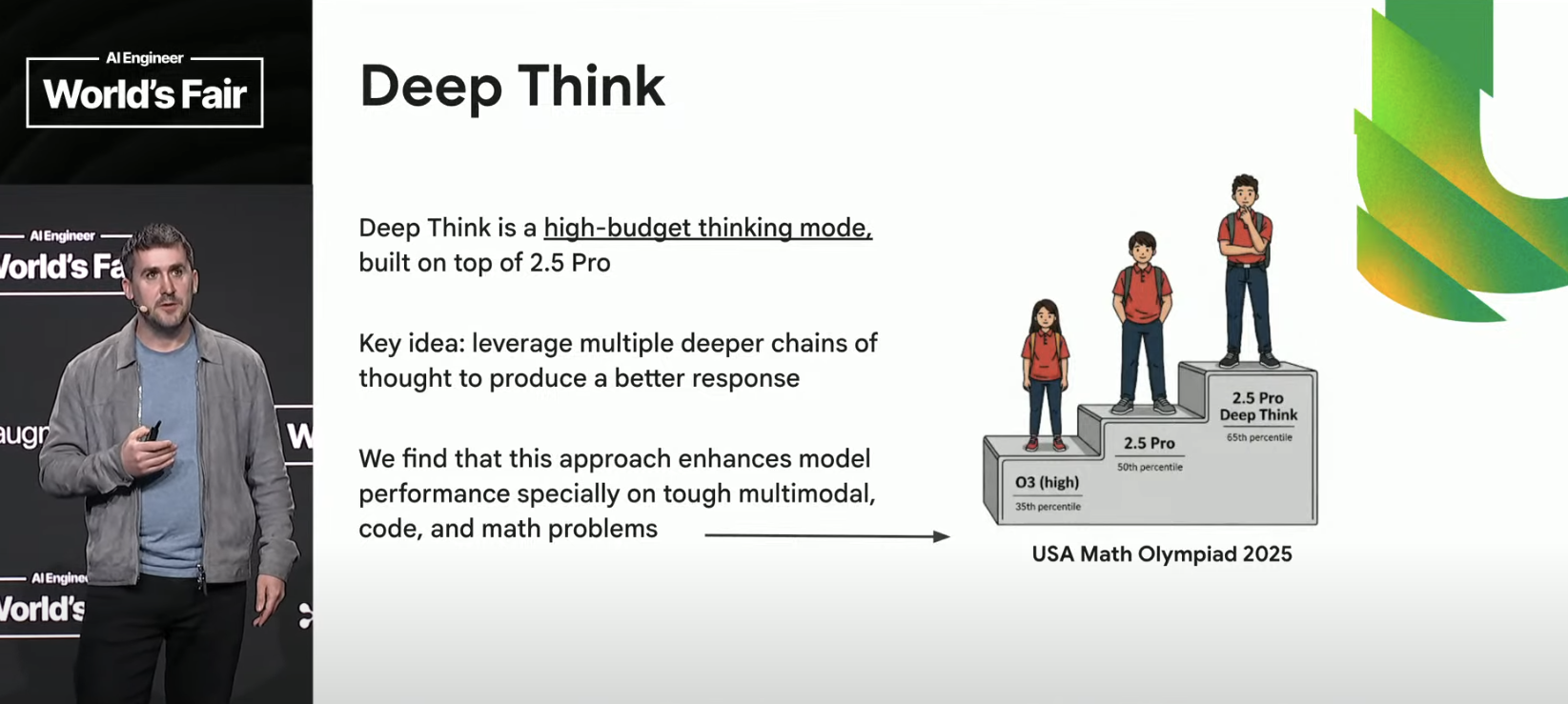
To close his keynote, Rae looks at what’s next—Deep Think, a high budget thinking mode for 2.5 Pro, which applies parallel, deeper chains of thought, yielding insane improvements on the toughest thinking challenges. Case in point: the 2025 Math Olympiad problem set, where OpenAI’s very good o3 reasoning model scored at the 35th percentile, 2.5 Pro reached 50th, and 2.5 Pro Deep Think all the way up to 65th percentile.
Containing Agent Chaos (use-container launch)
Speaker: Solomon Hykes (Dagger) – Session video
Solomon Hykes has serious credentials to be the co-founder of an open-source agent containerization framework—the dude created Docker!

Hykes kicked things off with an adjustment to an Anthropic slide: An agent is an LLM wrecking its environment in a loop:
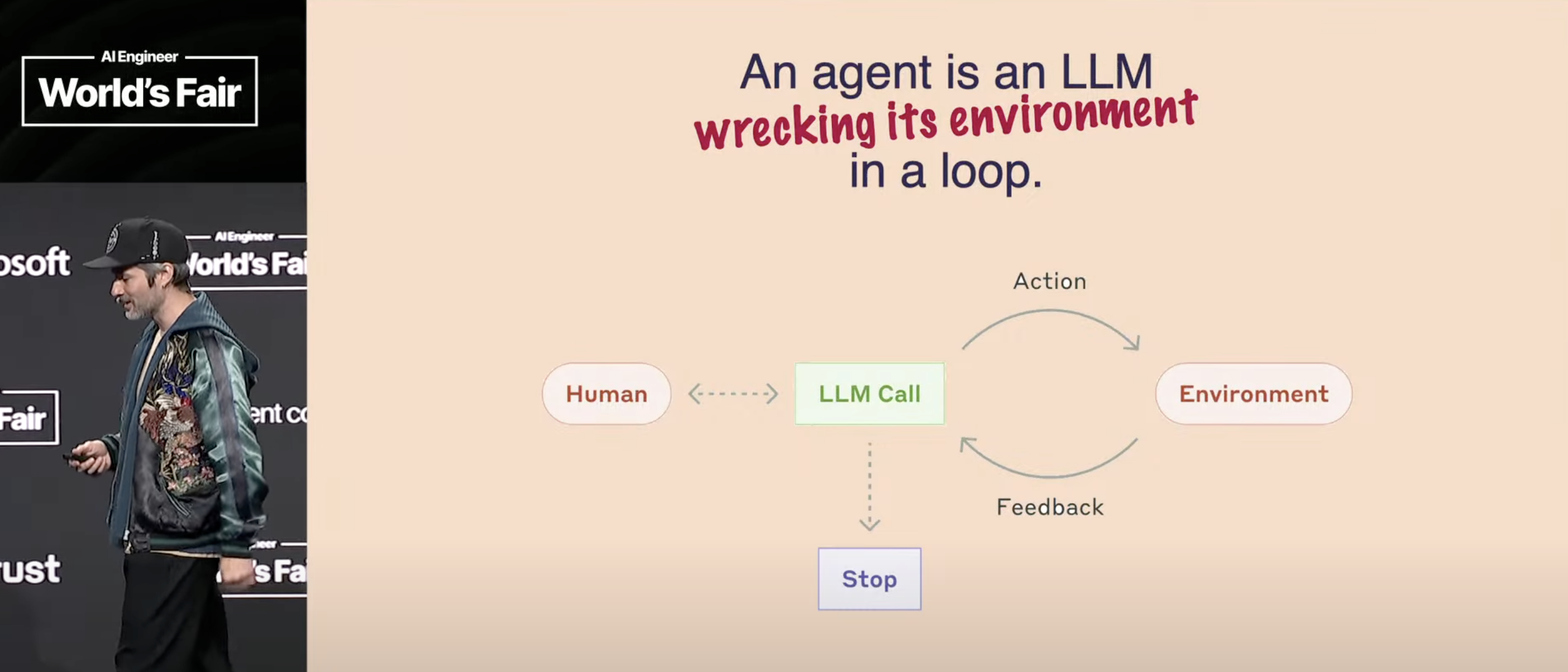
If we’re just running one agent—things aren’t so bad.

But hey, we want to scale it, we want to run 10 agents at once! Neither of today’s options are very appealing:

Hykes then talks about what we really want in order to safely operate and maintain control of 10 agents, and what the ideal environment looks like to make this work:

He points out that we already have the technology we need to deliver this: Containers + Git + Models, and mentions in passing that both containers and Git have a ton of capabilities that aren’t widely used by humans, but are perfect for agents. All we’re lacking is a native integration …
Hykes and Dagger suggest a solution: “container use for agents”—meant in same the sense as “computer use for agents” and “browser use for agents.” This is not sandboxing, which is about executing the output of agents. Rather, this is about creating complete, isolated development environments that agents do their development entirely inside of.

Against the advice of his team, Hykes launches into a wild and crazy live demo of (unfinished) Dagger, where he spawns about six Claude Code instances—and one Goose instance, just for fun—all iterating on a basic website project. Each instance–agent is iterating on the starting apps in complete isolation, with the orchestrating developer having the ability to merge any instance’s output if we like it. At the end, while the agents are madly spinning away, he open sources the Dagger project, live in front of the audience. I like Hykes, and I like Dagger—great stuff.
Infrastructure for the Singularity
Speaker: Jesse Han (Morph) – Session video
I didn’t resonate with Jesse Han’s presentation style and didn’t absorb much from the live presentation. Ah, the benefits of re-watching: I learned a lot more this time around.
I see a lot of overlap in Han’s and Hykes’s keynotes and products. Both have a lot to do with enabling environments that support the safe and effective spin-up and operation of clusters of agents. Both leverage containers, the power of Git and Git branches, and of course, agents. Morph’s Infinibranch: “All mistakes become reversible.” “All paths forward become possible.” Take action, backtrack, take every possible action.
Han’s chess demo was interesting; he contrasted a single AI working to pick the optimal chess move, with a swarm of agents on the Morph platform tackling the same problem using what he calls “reasoning time branching.” Han was fairly arrogant on suggesting that Morph’s closed platform would own the agentic execution environment space—a big contrast to Hykes, who open sourced their product on stage. Morph may go on to success, but I’d put money on Dagger winning market share.

Devin 2.0 and the Future of SWE
Speaker: Scott Wu (Cognition) – Session video
Scott Wu, Co-founder and CEO of Cognition, presented on Devin 2.0 and the evolution of AI-powered software engineering. I missed this session, so will withhold comment until I have a chance to view and absorb Wu’s talk.

Your Coding Agent Just Got Cloned
Speaker: Rustin Banks (Google Labs) – Session video
Rustin Banks from Google Labs talks about his work on Jules and asynchronous coding agents. Another missed session, I’ll comment later once I have a chance to view and absorb.
The Agent Awakens
Speaker: Christopher Harrison (GitHub) – Session video
Christopher Harrison from GitHub on the evolution of AI agents. I missed this session, so I’ll write later once I have a chance to review.

Don’t get one-shotted
Speaker: Tomas Reimers (Graphite) – Session video
Tomas Reimers, founder of Graphite, described how to leverage Al to test, review, merge, and deploy code. I missed this talk, but it looks good and I’ll write on it once I’ve watched.

Claude Code & the evolution of Agentic Coding
Speaker: Boris Cherny (Anthropic) – Session video
Claude Code wasn’t the first terminal-centric AI coding tool—among players with significant followings, those bragging rights probably go to Aider—but Boris Cherny provides a fascinating perspective on why model-maker Anthropic went the terminal route with Claude Code. I have observed first-hand how Anthropic’s Claude models have dominated the coding model space, with their lead seeming to accelerate with Sonnet 3.5, 3.7, and 4. Says Cherny,
The model is moving really fast. It’s on exponential. It’s getting better at coding very, very quickly, as everyone that uses the model knows. And the product is kind of struggling to keep up. We’re trying to figure out what product to build that’s good enough for a model like this.

I feel like programming languages have sort of leveled out but the model is on an exponential and the UX of programming is also on an exponential … ide devx has evolved quickly, and will continue to change even more quickly … that. And so with all this in mind, Claude Code’s approach is a little different.

We want to be unopinionated and we want to get out of the way. So we don’t give you a bunch of flashy UI. We don’t try to put a bunch of scaffolding in the way. Some of this is, we’re a model company at Anthropic, we make models and we want people to experience those models. But I think another part is we actually just don’t know, we don’t know what the right UX is. So we’re starting simple. So Claude Code is intentionally simple. It’s intentionally general. It shows off the model in the ways that matter to us, which is they can use all your tools and they can fit into all your workflows. So you can figure out how to use the model in this world where the UX of using code and using models is changing so fast.


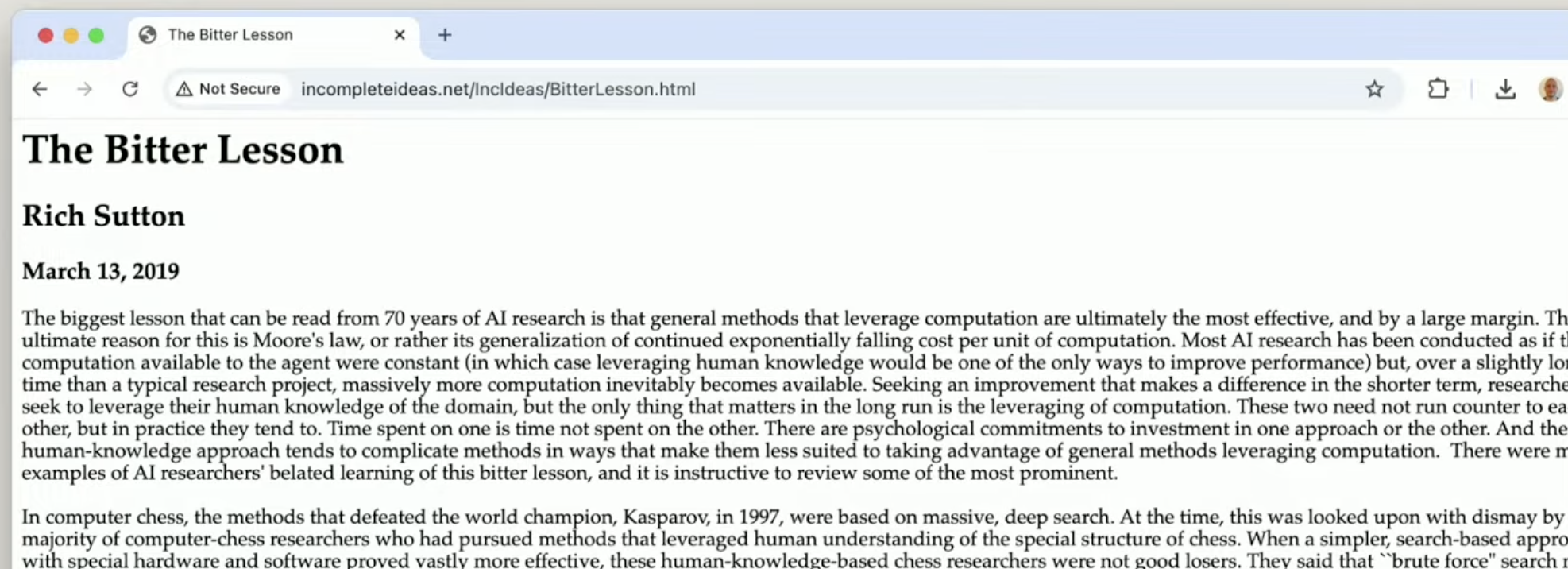
This is the bitter lesson. I have this like framed and taped to the side of my wall, because the more general model always wins and the model increases in capabilities exponentially and there are many corollaries to this. Everything around the model is also increasing exponentially and the more general thing even around the model usually wins.

Cherny describes four different modes of using Claude Code:
- From the terminal
- From the IDE (as an extension)
- As a GitHub app so you can @claude right in a GitHub issue comment
- Via the SDK, using Claude as a Unix utility

- Ask Claude Code about your code
- Teach Claude to use your tools
- Fit the workflow to the task, e.g. (explore › plan › confirm › code › commit) vs (tests › commit › code › iterate › commit) vs (code › screenshot › iterate)
- Plan mode (toggle via Shift-Tab)

- Create claude.md files: variants such as CLAUDE.md, CLAUDE.local.md, a/b/CLAUDE.md, ~/.claude/CLAUDE.md
- Context can also be made available as a slash command by putting markdown files under .claude/commands/
- Add to Claude’s memory by prepending # to something you want Claude Code to remember; CC will ask which memory location to remember into (project, user, etc.)

Software Dev Agents: What Works & What Doesn’t
Speaker: Robert Brennan (All Hands AI) – Session video
Robert Brennan, CEO of All Hands AI, is involved in one of those “AI name confusion” situations. His product (open sourced under an MIT license) used to be known as OpenDevin. And Devin is, of course, one of the pioneers of agentic coding. So what gives? I went to ChatGPT o3 to get the scoop:
The scoop from o3: OpenDevin launched in March 2024 as an MIT-licensed community effort to recreate Devin, the first AI software engineer. By August 2024 the project re-branded as OpenHands under the new startup All Hands AI, shedding its “clone” baggage while keeping Devin only as historical inspiration — see the rename announcement and the current OpenHands repo.
Brennan kicks off with this message:
Coding is going away … but that doesn’t mean that software engineering is going away. We’re paid not to to type on our keyboard but to actually think critically about the problems that are in front of us.

Brennan shared a great chart of the codegen landscape, with Tactical <=> Agentic on the X axis, and Consumer <=> Developer on the Y.
Now you’ve got these tools like Devin and OpenHands where you’re really giving an agent one or two sentences describing what you want it to do. It goes off and works for 5, 10, 15 minutes on its own and then comes back to you with a solution. This is a much more powerful way of working.

Brennan does a nice walkthrough of how coding agents actually work, and then shares tips on how to be most effective working with agentic coding. One point he makes, which I can affirm based on my own experience, is that you shouldn’t be afraid to throw code away.
I also like to remind folks that in an AI-driven development world, code is cheap. You can throw code away. You can you can experiment and prototype. I love, if I have an idea, like on my walk to work, I’ll just tell OpenHands with my voice, “do X, Y, and Z,” and then when I get to work, I’ll have a PR waiting for me. 50% of the time, I’ll just throw it away. It didn’t really work. 50% of the time it looks great, and I just merge it, and it’s awesome.

Definitely worth watching.
Beyond the Prototype
Speaker: Josh Albrecht (Imbue) – Session video
Josh Albrecht, CTO of Imbue, whose main focus is Sculptor, an AI tool that’s still in the early research preview. What does it do?
Sculptor is a coding agent environment that applies engineering discipline to catch issues, write tests, and improve your code—all while you work in your favorite editor. Sculptor is the first coding agent environment that helps you embed software engineering best practices. Sculptor runs your code in a sandbox, letting you test code safely, solve issues in parallel, and assign tasks to agents, working alongside any editor. Use Sculptor to resolve bugs, write tests, add new features, improve docs, fix style issues, and make your code better—whether it was written by a human or an LLM.
Albrecht’s session tagline is Using Al to Write High-Quality Code and clearly his work on Sculptor gives him the background to speak intelligently on the subject.
Vibe coding output versus production-shippable code.
‘What is wrong with this diff?’ Allowing another Al system to come and take a look at this and understand like hey are there any race conditions? Did you leave your API key in there etc. We want to think about how do we help leverage Al tools not just to generate the code but to help us build trust in that code.

Four tips for preventing problems in AI-generated code:

Regarding writing specs:
In Sculptor, one of the ways that we try to make this easier is by helping detect if the code and the docs have become outdated. So it reduces the barrier to writing and maintaining documentation and dock strings because now you have a way of more automatically fixing the inconsistencies. It can also highlight inconsistencies or parts the specifications that conflict with each other, making it easier to make sure that your system makes sense from the very beginning.
Three tips for detecting problems in AI-generated code:

Things you can ask an LLM:

Solid, practical advice all the way through.
Ship Production Software in Minutes, Not Months
Speaker: Eno Reyes (Factory AI) – Session video
I was blown away when I first heard Eno Reyes and Matan Grinberg on the Latent Space podcast, and I was excited to hear Reyes talk in person. To me, Factory stands out as the most serious AI tool for engineering at Fortune 500 scale, addressing Fortune 500 level problems. Factory also stands out as pioneering in the exploration of AI UX that isn’t bolted on to the 20-year-old IDE paradigm. As Reyes says:
It seems like right now we’re still trying to find what that interaction pattern, what that future looks like. And a lot of what’s publicly available is more or less an incremental improvement. The current zeitgeist is to take tools that were developed 20 years ago for humans to write every individual line of code—tools that were designed first and foremost for human beings. And you sprinkle AI on top and then you keep adding layers of AI and then at some point maybe there’s some step function change that happens. But there’s not a lot of clarity there in exactly what that means.
Reyes shares Andrej Karpathy’s quote about English-as-programming-language:
But he goes on to confront the idea that this means vibe coding. He speaks to the importance of context, and working with the kind clientele they do, Factory certainly has good data behind this:
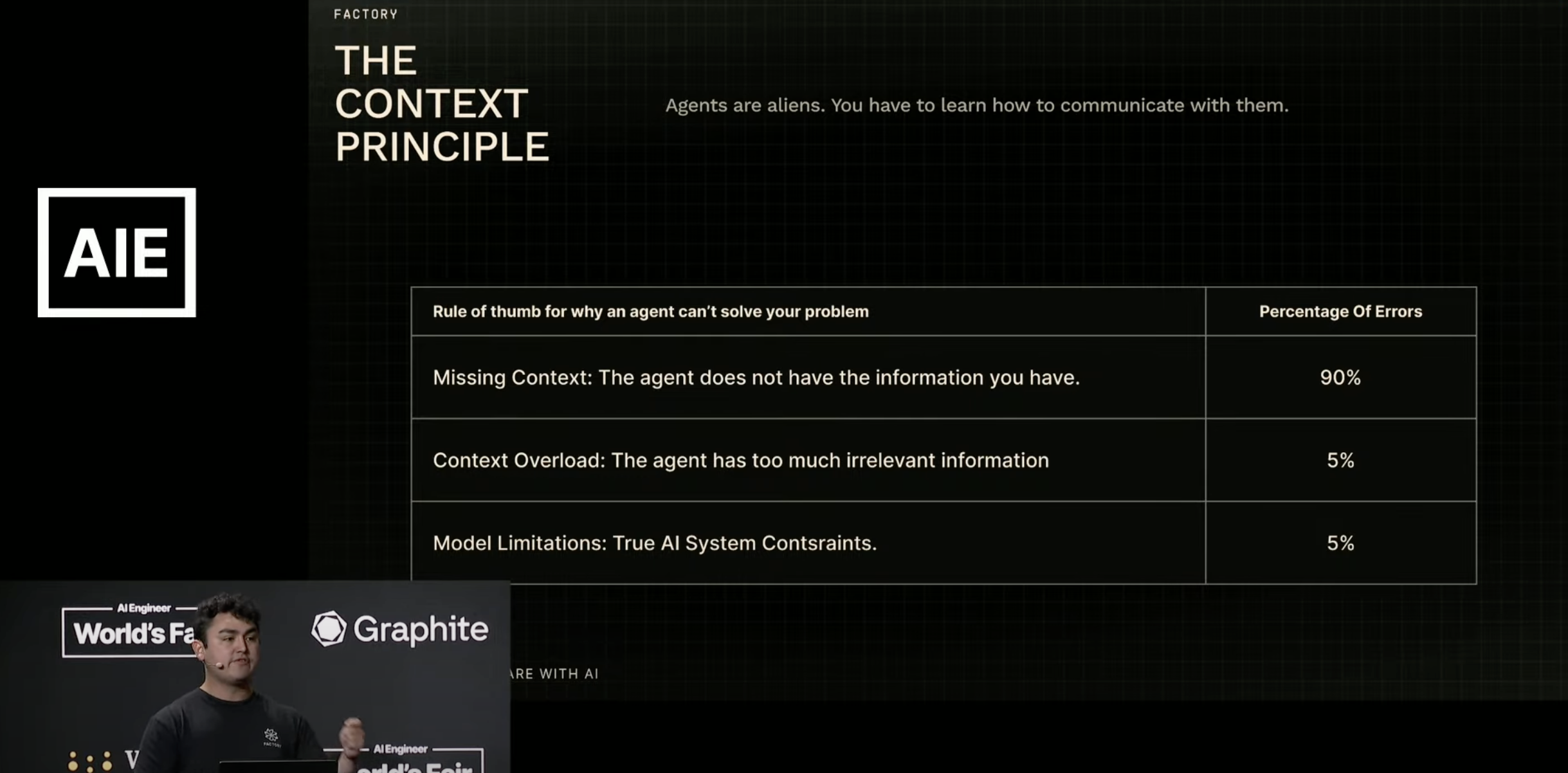
And it’s very clear when Reyes talks about Planning with AI that the F500 problem space Factory works in isn’t Tiny Teams territory:


In the agile, human coding world that preceded AI coding, I have tended to streamline if not completely avoid what I saw as bloated processes based around heavyweight artifacts like Product Requirements Documents (PRDs). But in the new world, especially at F500 scale, it makes sense that we are coming full circle. Reyes moves on to a Site Reliability Engineering (SRE) example, show context and documents coming together in a loop where the system gets smarter and smarter, moving from helping to diagnose incidents to suggesting “I’m seeing a pattern here—why don’t we fix this.”
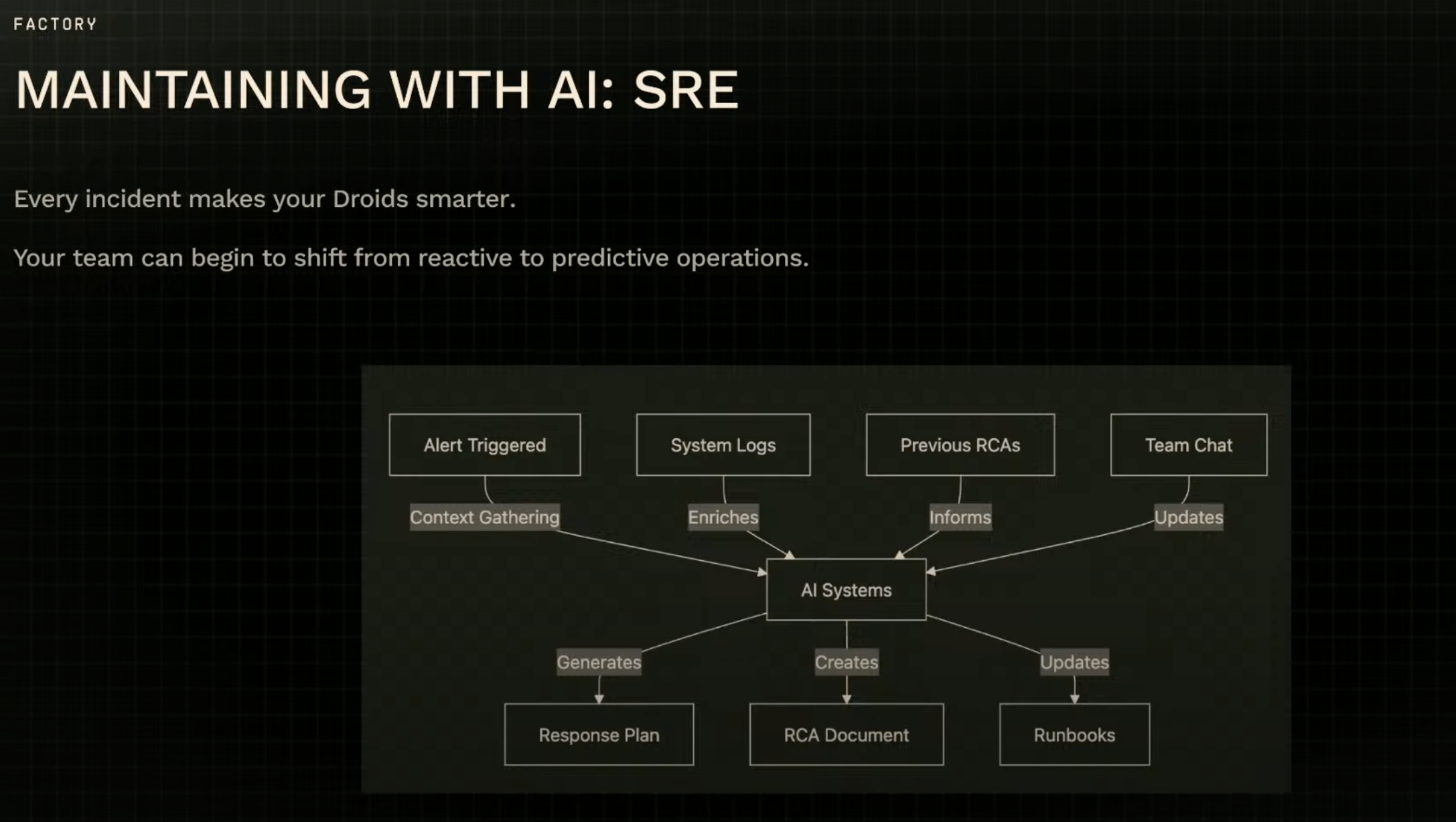
Reyes closes by addressing the subject of AIs replacing engineers:
AI agents are not replacing software engineers. They’re significantly amplifying their individual capabilities. The best developers l know are spending far less time in the IDE writing lines of code. It’s just not high leverage. They’re managing agents that can do multiple things at once that are capable of organizing the systems and they’re building out patterns that supersede the inner loop of software development and they’re moving to the outer loop of software development. They aren’t worried about agents taking their jobs. They’re too busy using the agents to become even better at what they do. The future belongs to developers who understand how to work with agents, not those who hope that Al will just do the work for them. And in that future, the skill that matters most is not technical knowledge or your ability to optimize a specific system, but your ability to think clearly and communicate effectively with both humans and AI.
Mixed in with his slides, Reyes includes several video demos of Factory “Droids” in action—their name for independent agents. Very much worth watching in full.
Trends across the AI Frontier
Speaker: George Cameron (Artificial Analysis) – Session video
Artificial Analysis maintains a multidimensional and deeply impressive treasure trove of data about LLMs. George Cameron starts by confirming Simon Willison’s declaration that it’s been an insane period of LLM development. Cameron starts with the past 12 months in frontier models: OpenAI still in the lead, but the frontier more competitive than ever:
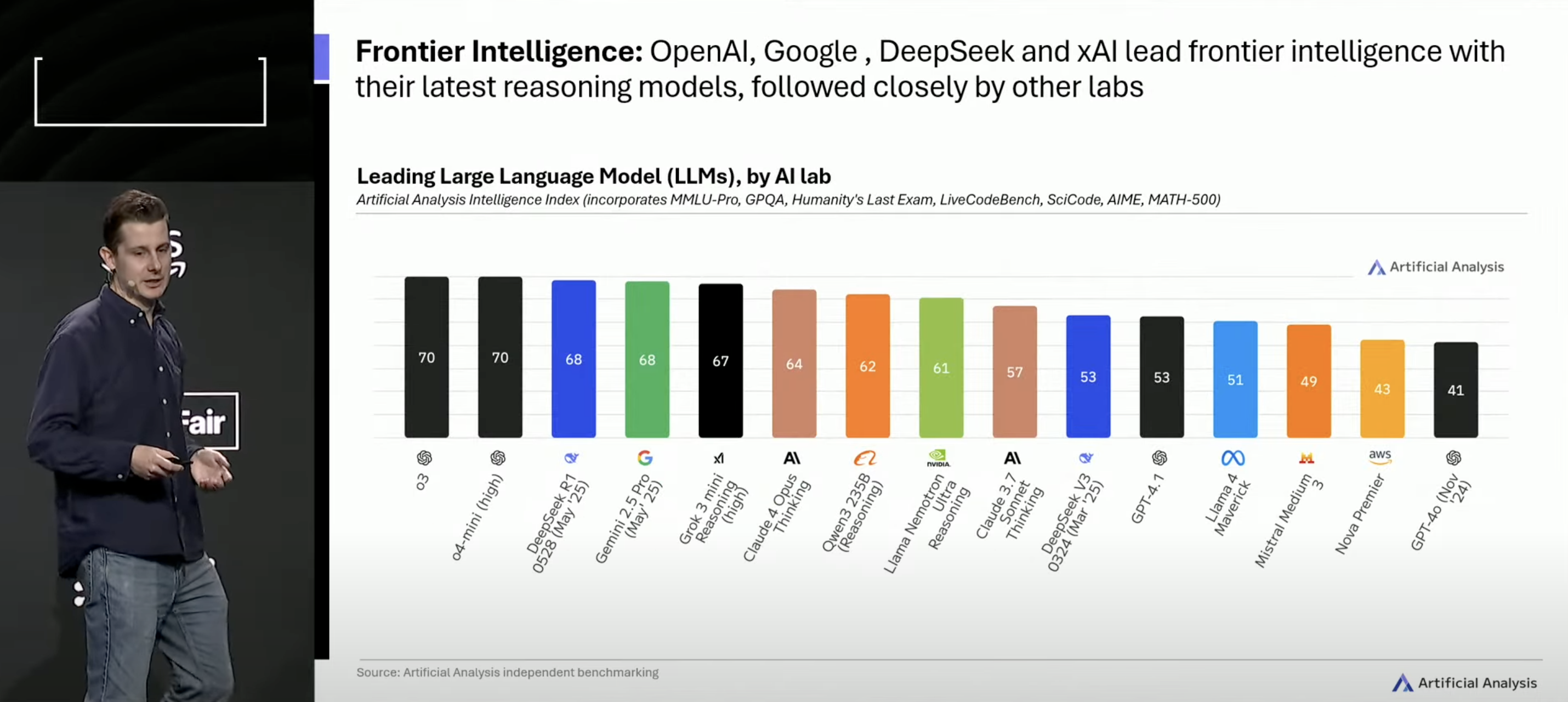
Note: less than 2 months after Cameron’s presentation, there’ve been significant changes in the frontier intelligence rankings:
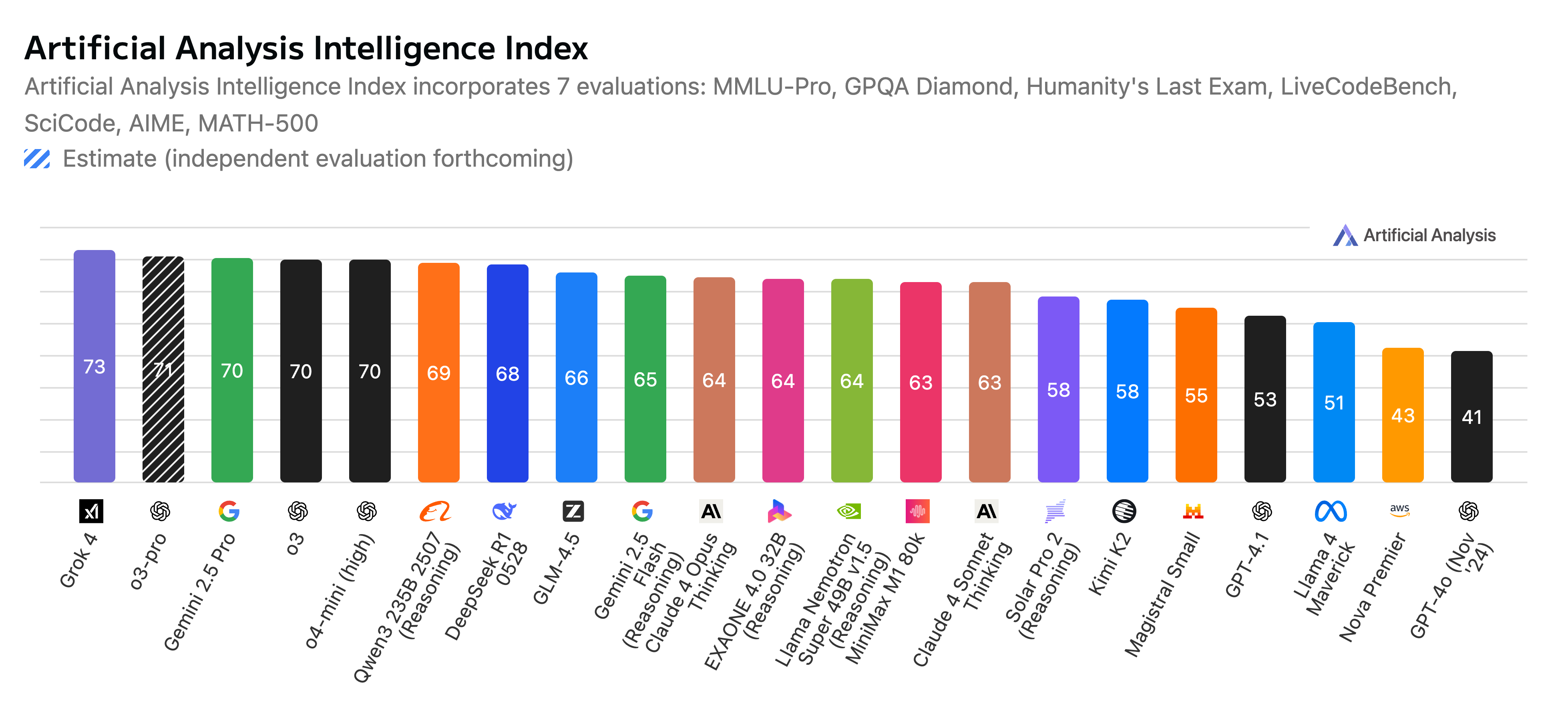
Cameron next points out that there are actually more than one frontier in AI:
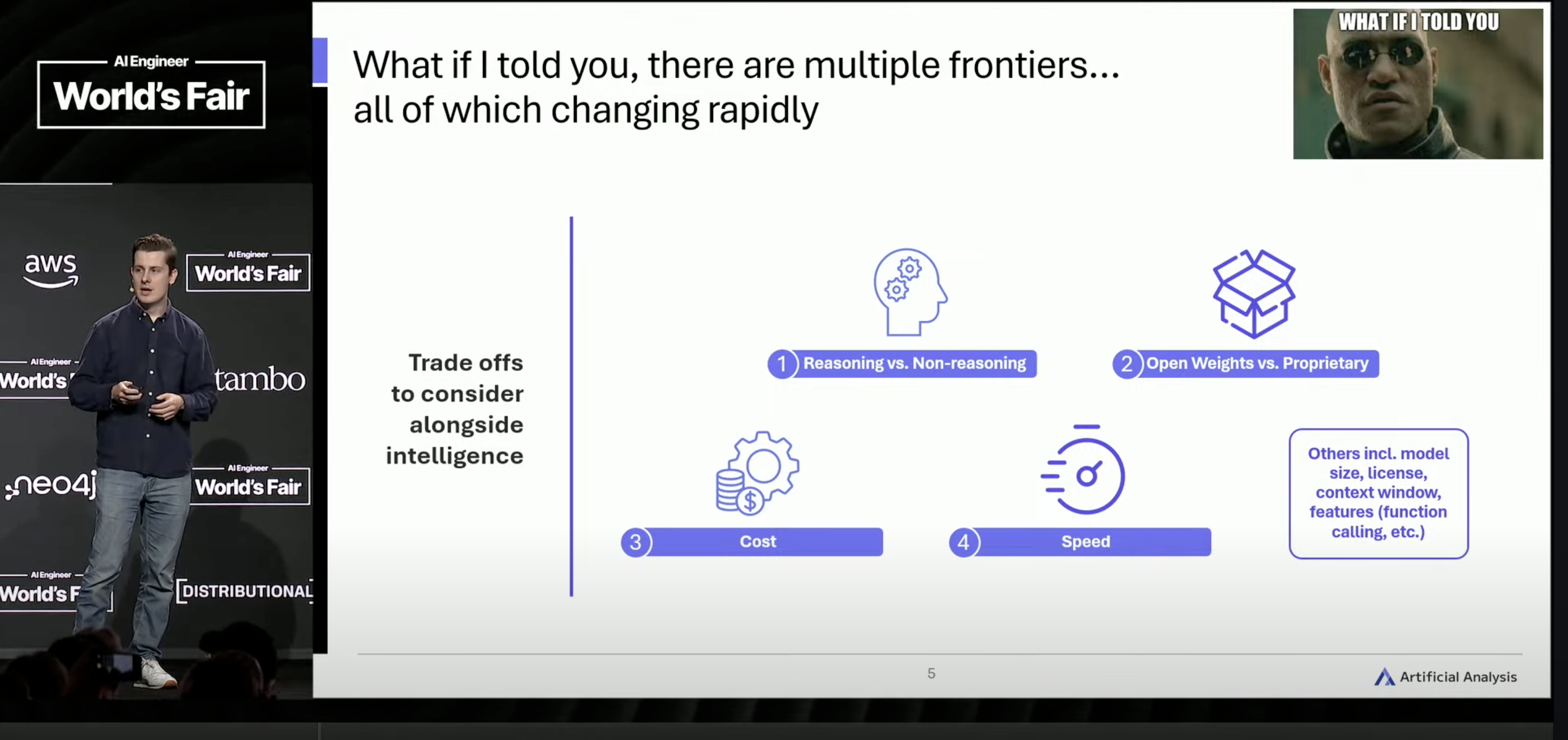
He goes on to explore each category. Super-sharp analysis; AA is a new go-to for me when I need this type of comparative. The one domain where I’m skeptical of AA’s ratings: coding. Either my (and the world-at-large’s) experience is mistaken, or AA’s coding benchmarks are borked. Otherwise, though, I stick by my pronouncement: a multidimensional and deeply impressive treasure trove. Check them out.
State of AI Engineering 2025
Speaker: Barr Yaron (Amplify Partners) – Session video
Amplify Partners recently completed their 2025 State of AI Engineering Survey, and partner Barr Yaron presented a number of early findings. Money slide for me: top newsletters and podcasts:

Fun Stories from Building OpenRouter and Where All This is Going
Speaker: Alex Atallah (OpenRouter) – Session video
I had quite a few knowledge gaps filled in at the World’s Fair; one big one was near-total ignorance of OpenRouter. In reality, it has taken me World’s Fair plus two months for the OpenRouter concept to really sink in, and for me to understand the use cases where it makes a ton of sense. I’m just about to set up an OpenRouter account for use on a proof of concept project where I want to avoid setting up many individual direct accounts with model makers. I send my thanks to Alex Atallah, founder of OpenRouter, for helping reduce my ignorance through this talk.
So what are the fundamentals of OpenRouter? API to access all language models; and also, because they are a marketplace, an unparalleled source of data about who is using what models. Pay in one place, with near zero switching cost. >400 models, >60 access providers, many payment methods including crypto.

The founding story and evolution of OpenRouter is fascinating: a journey from experiment to marketplace. Major labs started banning uses. The open source race and “Llama storm.” First successful model distillation: Alpaca, trained for $600. OpenRouter was initially a place to collect all these. Window.ai chrome extension allowing users to choose their own models. OpenRouter’s official launch in May ‘23. OpenRouter wasn’t a marketplace originally – started out with just one primary and one fallback provider for any given model. Then a great proliferation of providers emerged, where a single model being might be available from many providers with different price points and supported feature sets (e.g. with or without structured output). This pushed OpenRouter to become a marketplace.
Then it emerged that closed models couldn’t keep up with inference demand on their own platforms. OpenRouter helped developers boost uptime by allowing routing to different sources for closed models e.g. Claude models on Amazon Bedrock. Check out this uptime chart to get a feel for the benefits:
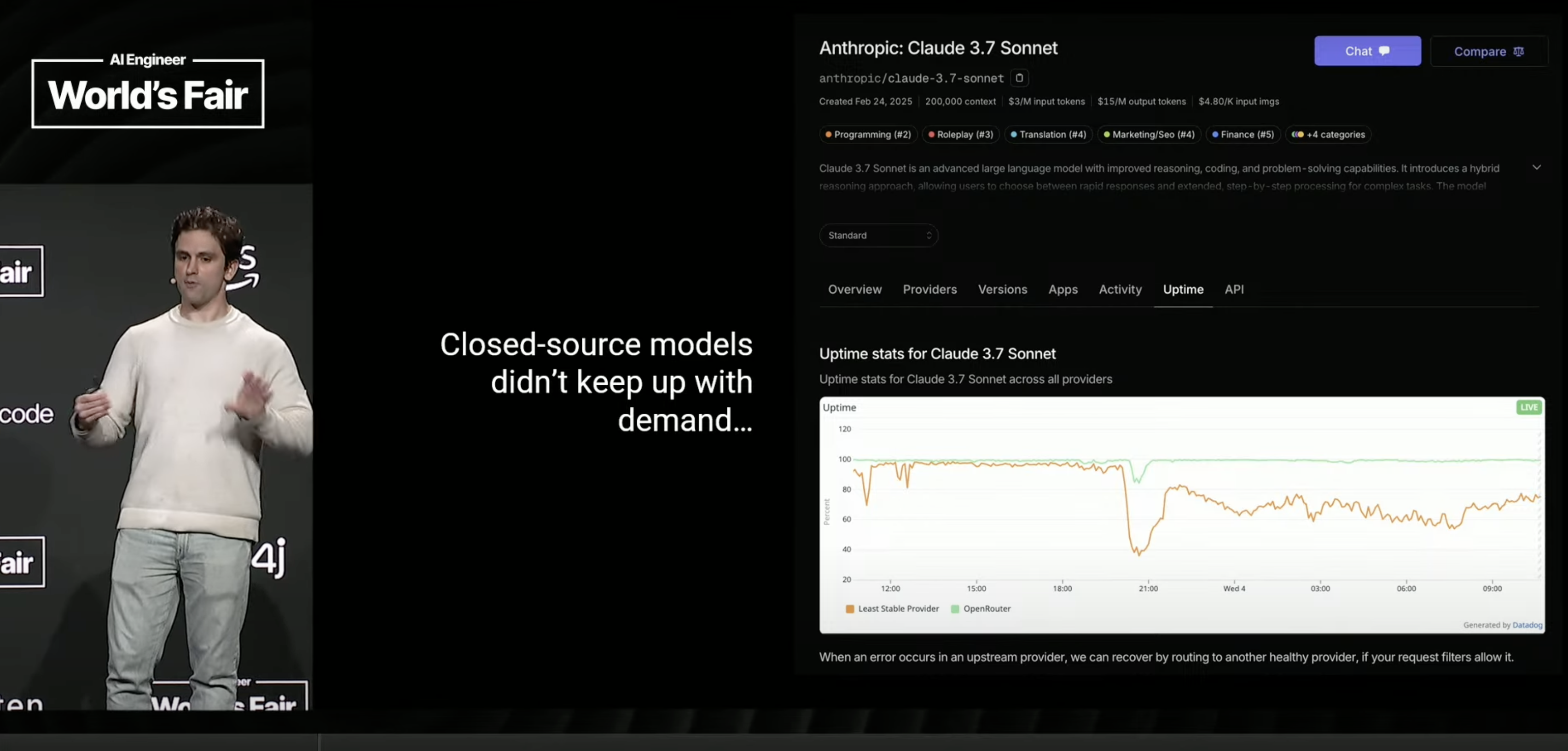
With all the fantastic data OpenRouter has at its disposal, what do they believe the future looks like?

I love the direction OpenRouter is taking with their API, adding a plugin-like system that augments, transparently and in real time, the capabilities of *all models. Atallah mentions two examples: web search and PDF data extraction.
All told, OpenRouter is a major addition to my toolbox, and this session is a must-watch.
The New Code
Speaker: Sean Grove (OpenAI) – Session video
Earlier in the day, Eno Reyes quoted Andrej Karpathy, “The hottest new programming language is English,” and emphasized structured documents like PRDs as an essential way to communicate with AI agents. Picking up where Reyes left off, OpenAI’s Sean Grove talked on “The New Code—Specs.”

Grove did a quick audience survey, asking how many people “coded” and how many of them felt that code was their primary output:

He then confronted this belief, suggesting that code is more like 10-20% of the output.

What’s the far larger slice of impact? What he calls “structured communication.” Here’s what it looks like:

He sees structured communication as the key bottleneck in software engineering, and predicts that it will only get more painful as models get better.

In the near future, the person who communicates most effectively is the most valuable programmer. And literally, if you can communicate effectively, you can program.
Vibe coding – why it feels great – fundamentally about communication first, coding second. But the weird thing: we communicate via prompts to express our intentions, our values. We then produce an artifact, code, and throw away the valuable stuff, the prompts! That’s like throwing away the source code and just keeping the binary compiled output. This leads Grove to emphasize that written specs are critical, and why:

Grove uses another analogy: specs are like a lossless format, while code is lossy. Specs contain more information, code is a lossy representation that has lost some of that information.
He walked us through an example relating to OpenAI’s model specs (intentions and values) which are now published; and a recent sycophancy regression identified in an updated version of their GPT-4o model. The model spec contained very specific anti-sycophancy language, but the behavior GPT-4o update was clearly not aligning with those specs. As a result, the team was able to confirm “bug, not intentional,” roll back the update, and fix the problem. The written specs acted as a “trust anchor” here, a trustworthy source on how the model should behave.
One more corollary: whoever writes the specs is the programmer.

Grove’s talk, paired with Reyes’ talk earlier in the day, form an AI Spec Sandwich. Welcome to the new programming.