OpenAI is constantly firehosing us with new capabilities. It’s tough just to keep up with the announcements, let alone deeply understand the new offerings at depth. The only way I know to develop this kind of deep understanding is to build something real and non-trivial.
I was fortunate to have a somewhat complex personal need, just as the new GPT-4 Vision model and updated Chat Completions API landed in my OpenAI account. The tale of my exploration follows.
Note—Click any image to zoom
Sept. 25th: “ChatGPT can now see, hear, and speak …”
OpenAI had teased vision support earlier, but the actual announcement of Vision availability happened on Sept. 25th under the above headline.
I’m not an OpenAI VIP, sorry. I’m just a paid ChatGPT Plus user and Tier-1-going-on-Tier-2 API user. I don’t get early access; I get late access.
So while OpenAI announced GPT-4 Vision on Sept 25th, it didn’t show up for me until late October or early November. OpenAI doesn’t communicate actual availability of features to its retail customers, and so all I know for sure is that I noticed Vision had showed up in my ChatGPT+ sometime in early November.
My burning need: family heirloom recipes
During our August vacation at the family lake house, we uncovered a treasure-trove of recipes, which my daughter-in-law Julie was kind enough to capture using the iOS Notes app and share in PDF format. On my to-do list since then had been figuring out how to get those recipes into a recipe app. I use Paprika 3, while Julie has been trying out Recipe Keeper.


What the family really needs is both a great facsimile of the original paper recipe (high resolution, correct orientation, zoomable), and a fully-digital recipe with all the goodies that apps like Paprika and Recipe Keeper give you—ingredient scaling, store lists, easy sharing, and so on.
Paprika has been around forever, and several years back I had tried importing legacy recipe images, but at that point in time I wasn’t able to get the “high resolution, correct orientation, zoomable” solution desired. So I was wondering if Julie had any luck with Recipe Keeper and I began poking around the current Paprika.
In the end it turned out that the current version of Paprika 3 has quite strong image support, while in limited testing, I had trouble getting Recipe Keep to handle image orientations correctly. So the recipe app I was already using looked to be the best solution. Decision made.
We still had a lot of work ahead of us, though—laboriously transcribing from those torn, stained, mostly handwritten family treasures. And this particular trove is probably only 20% of the full library; my brother has the larger collection, probably at least 3X as many, and my sister and wife have others. This was shaping up to be a long side project.
Nov. 14th: Recipe image => ChatGPT Plus with Vision
So when I discovered that my ChatGPT Plus account now had the “new stuff” including vision support, I had a ready-made test case for Vision.
I know for sure that it was November 14th when I began toying with it. My first (failed) Vision request was:
This first request caused GPT-4V to puke—PDFs aren’t considered an image format. I used macOS Preview to export a png file from another one my recipe PDFs and fed that to Vision. This was the input:

I fully expected an interesting failure. I’ve been doing technology for over four decades, which coincidentally is just about how long OCR—optical character recognition—has been available for personal use. And OCR has sucked for all of those decades. OCRing scans of printed documents is painful and error-prone. But with our legacy recipes, we faced much worse, like Margie Johnson’s Cheesecake above—typed with a worn ribbon, wrinkled, stained.
My expectations were low, but on the other hand, GPT-4 blows my mind several times a week, so what the heck, let’s see what happens.
OCR is dead, long live Vision
This was GPT-4V’s response to that image:

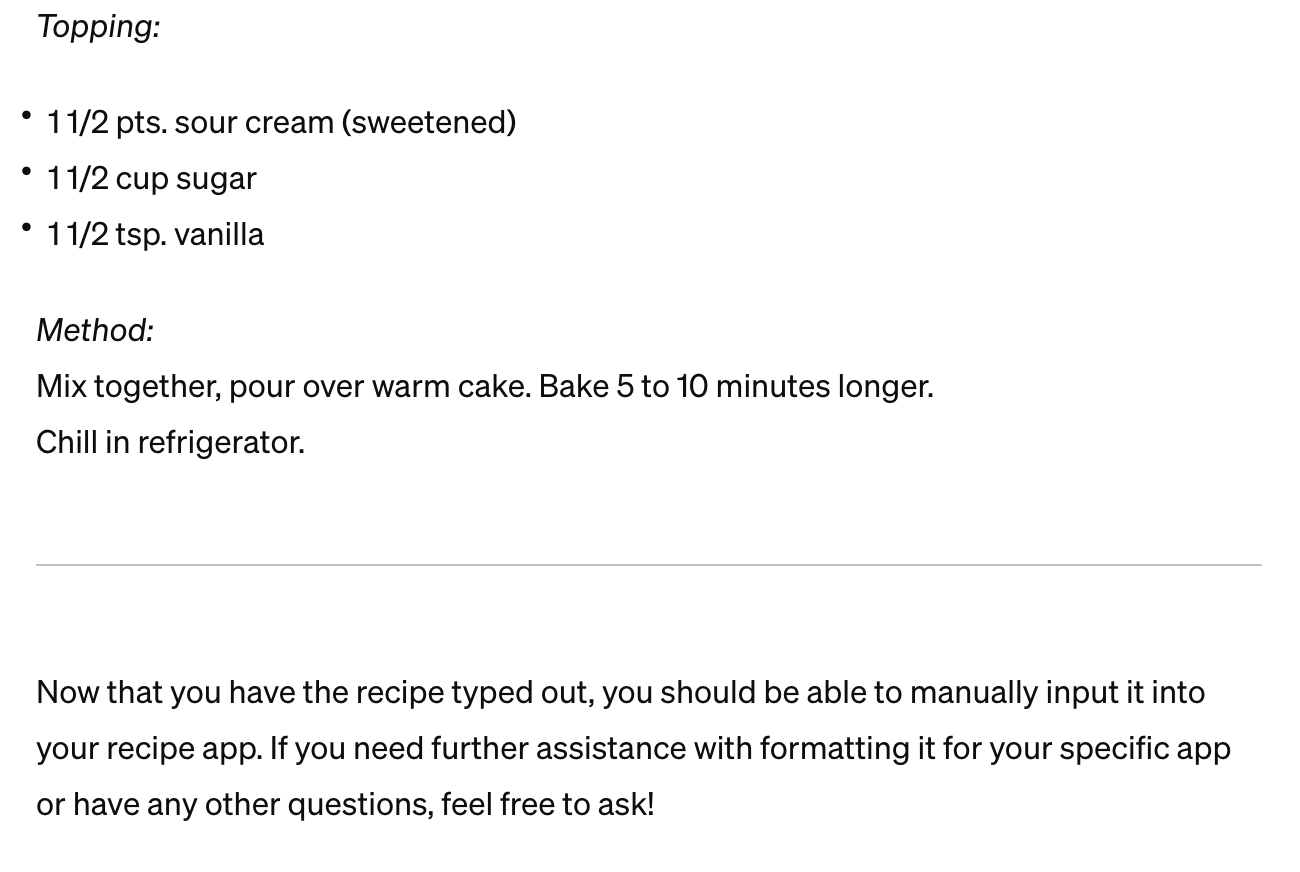
I was expecting “maybe a little better than your grandma’s OCR” but this was shockingly far beyond that. Not only did 4V get almost everything correct from the Margie recipe, worn ribbon, wrinkles, stains and everything, but GPT-4V understood it and organized it for me. For example, 4V correctly “gets it” that this recipe had three main elements—crust, filling, and topping—when the recipe never uses any of those words! And then helpfully organizes its output that way.
With traditional OCR, at best I’d get most of the words, in the order they appear on the page. But this recipe isn’t plain text that reads left-to-right, top-to-bottom. Take for example the initial crust block that uses the typist’s trick of using a column of “)” characters to create a column separator: ingredients in the left column, instructions in the right. OCR would just give me a useless left-to-right, top-to-bottom character stream; but GPT-4V understood what it was seeing and placed the directions below the ingredients in a structured manner. Holy shit.
“Guys? Guys? This has structure. I’m [seeing] structure.”
I love the scene in the movie Contact where Kent, the blind SETI researcher, says:
Guys? Guys? Um…
You know those interlaced frames that we thought were noise?
This has structure. I’m hearing structure.
Seeing that chat response, it wasn’t just that I was getting better text than old-school OCR. GPT-4V was giving me structure, without my even asking. No surprise that my next question was:
Is there a standard interchange format for recipes?

Oh ho, I see Paprika on the list!
Dec. 17th: Image => ChatGPT-4V => YAML => Paprika import
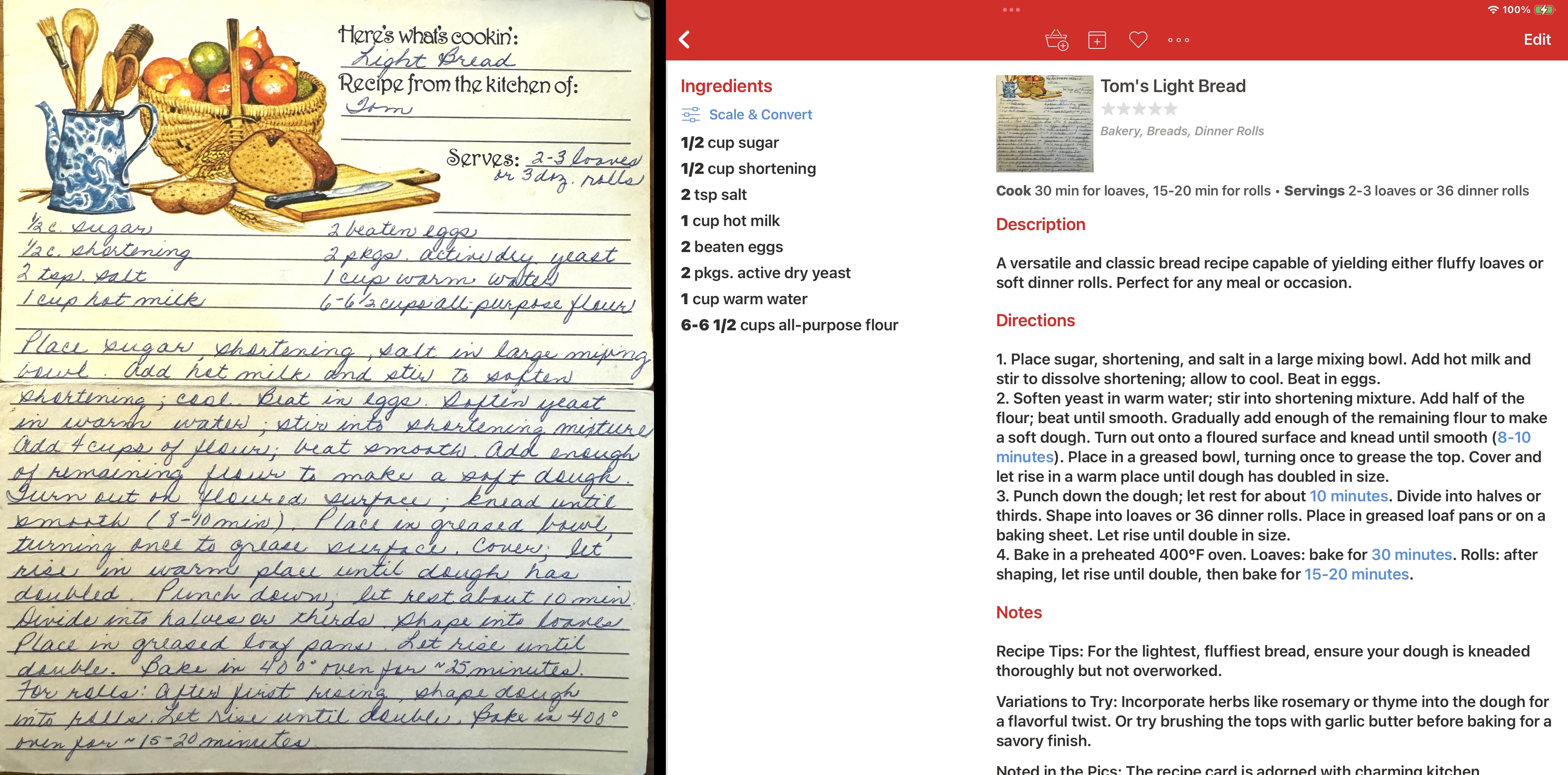
I explored the various file formats that Paprika could import. Most of these were specific to what other recipe apps could export, to enable migration onto Paprika. But Paprika also supports a more generalized import from YAML format, and provided a couple of helpful examples. That looked like my best option, and then began the work of convincing ChatGPT to take a recipe image, and instead of giving me semi-structured text output, to instead produce Paprika-flavored YAML. It took a bit of research and several tries, but eventually I was able to feed in an image and get Paprika-compatible recipe YAML back. Here’s the source image and YAML output:

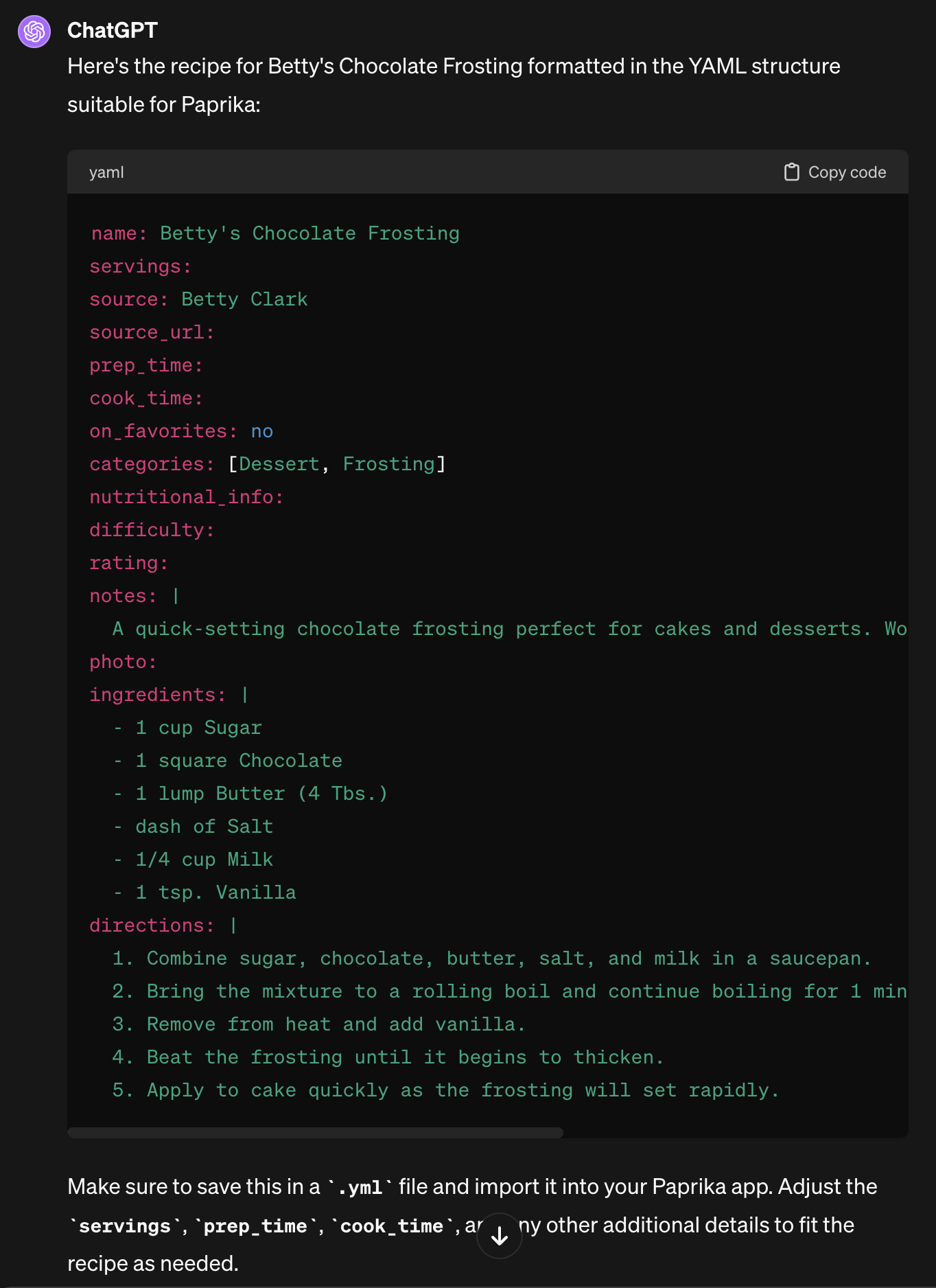
And here’s what it looks like when imported into Paprika, iPad and iPhone versions:
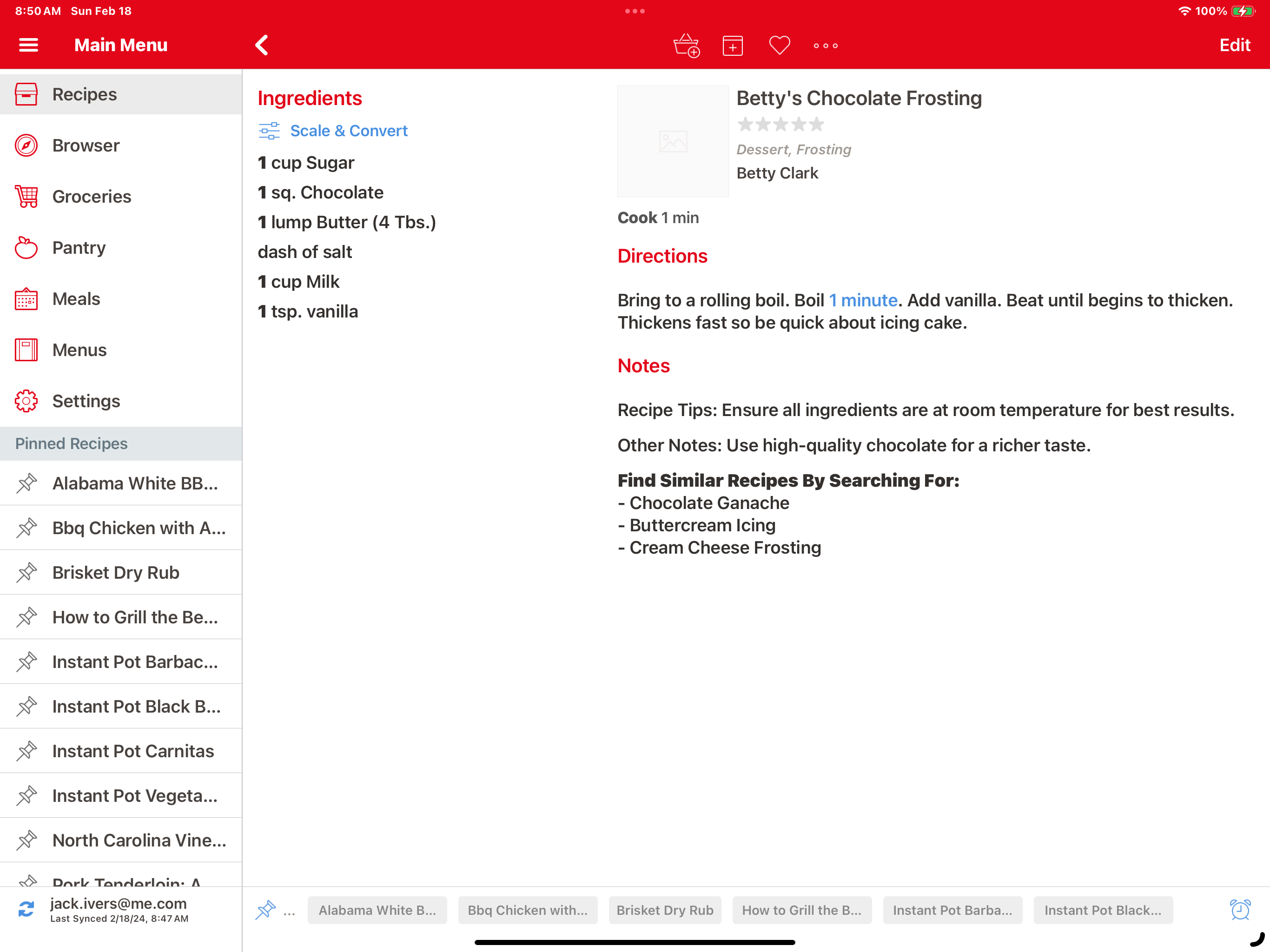
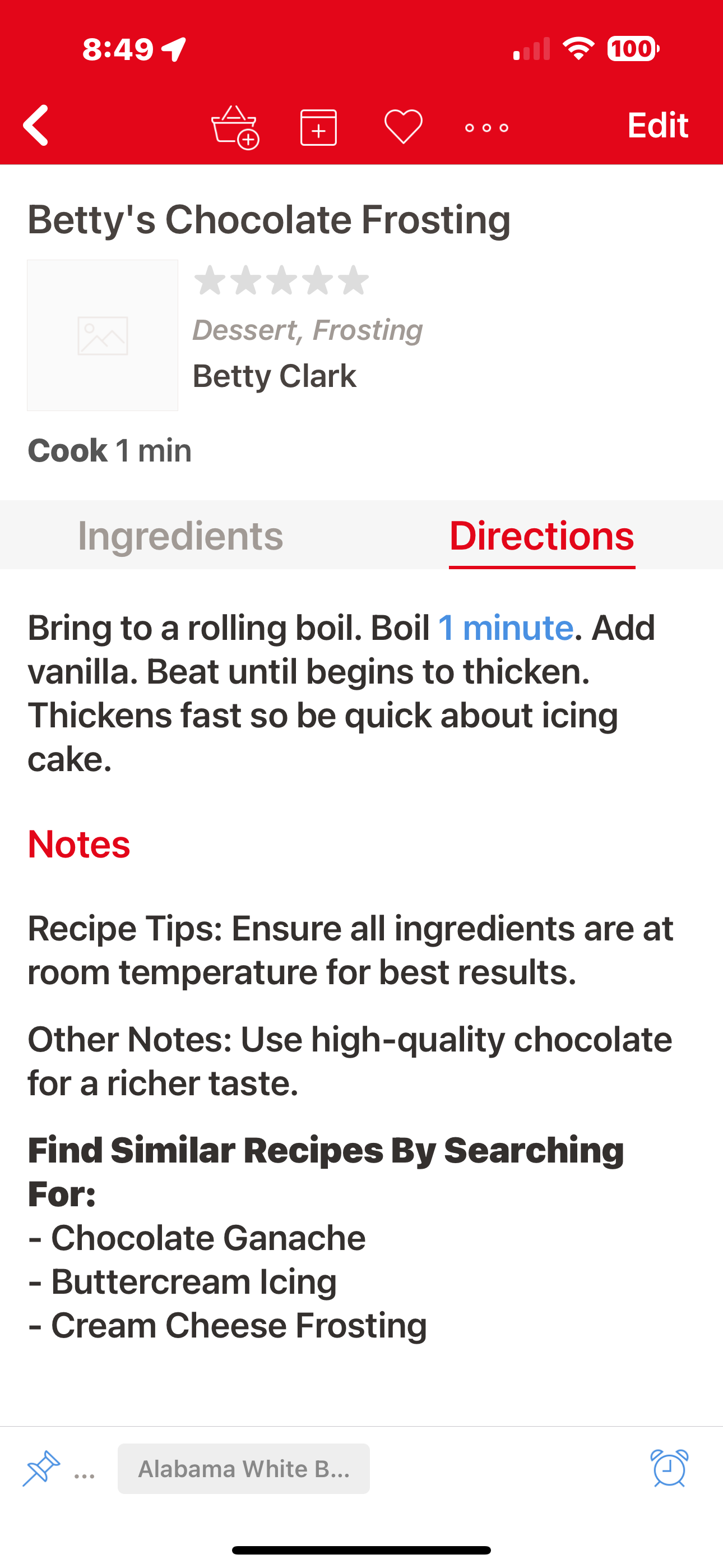
Now, ChatGPT was doing most of the work—image in, importable YAML out. That left me light years ahead of the mess I had been facing—laborious manual transcription or parsing garbled OCR output.
Late December: Automating in Python
Despite the impressive gains compared with the time I would have spent manually transcribing or old-school OCRing, interactive-chatting my way through hundreds of recipes was going to be quite time-consuming. ChatGPT also has a tendency to “lose the thread” on long-running chats. Finally, though Paprika is capable of importing YAML files with an embedded BASE64 image, it was beyond ChatGPT’s capabilities to produce that kind of YAML output. As a result, I had to first import the generated YAML into Paprika, then manually add photos.
So automating the process was looking attractive—eliminate interactive sessions in favor of directly scripting calls to the OpenAI API.
I picked Python as a logical choice to script in, figuring it’d have libraries for anything needed, and because GPT-4 is very good at Python coding; I was not disappointed on either front. Unfortunately I didn’t have much choice about which OpenAI API I’d need to use. Back then—and still to this day—the only API that supports GPT-4 Vision is a feature-reduced Chat Completions API:

This limited Chat Completions API available with Vision models is fine for simply automating something you’ve been doing using the chat interface; but it’s significantly less powerful than the full-strength Chat Completions API available for text input, let alone the new Assistants API. More on this later.
In any case, off I went scripting Chat Completions from Python:
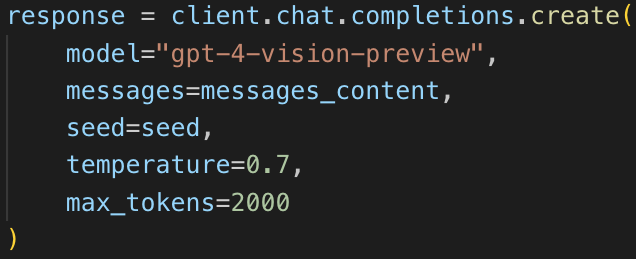
A few days before Christmas I had Python successfully scripting images => Chat Completions API => YAML output, and soon after added a BASE64-encoded image to the YAML output. I also added directory processing, so the script would run through an entire directory of image files and produce YAML-with-image output for each recipe, in a single script run.
Early January: From YAML import to JSON cloud sync
More than a few of our heirloom recipes had multiple images—for example the front and back of a recipe card—and while GPT-4 Vision handled multiple images perfectly, I never had any success getting Paprika to ingest more than one image from a YAML file.
In searching for a solution, I discovered a whole community of recipe hobbyists who loved the Paprika app and found ways to creatively use Paprika’s cloud sync API to build useful tools like a recipe exchanger that synced across multiple Paprika accounts. Paprika’s cloud sync is the native interface of the app itself, and so by definition supports all the app’s capabilities, including multiple photos per recipe, so it was able address the apparent limitations of YAML image importing. Publishing direct-to-cloud also saved the manual YAML import step, another key win.
I dug in and by New Years day had cloud sync operating, and had multiple photos loading into Paprika soon after:

Later January: JSON Mode to overcome structured output fragility
The Chat Completions API, paired with the gpt-4-vision-preview model, is wonderful in its multimodal-ness. Unfortunately, this pairing is significantly restricted compared to the same API paired with the latest gpt-4-turbo-preview model. The even-more-powerful Assistants API currently doesn’t support image input at all.
What appears to have happened is this. OpenAI wanted to get the GPT-4 Vision model, announced on Sept. 25th, into the field as early as possible. But OpenAI likewise wanted to get the significantly updated GPT-4 Turbo model with corresponding Chat Completions API updates, along with the all-new Assistants API, into developers’ hands ASAP also, and did so at the DevDay event on Nov. 6th. But full integration of Vision into these updated and new APIs wasn’t (and still isn’t) ready. OpenAI’s compromise solution is what we have at the moment.
Why do I care about the new capabilities launched at DevDay? My immediate problem is that the Chat Completions API with Vision isn’t 100% reliable at producing structured output like YAML or JSON. It usually works, but sometimes doesn’t, depending on the content fed to it. This leads to a constant prompt engineering cycle, with prompts constantly being tweaked to avoid output breakage.
At the DevDay event on Nov. 6th, OpenAI announced JSON Mode, where using the response_format parameter, you tell the model to “constrain its output to generate a syntactically correct JSON object.” That’s exactly the solution I need to get higher reliability structured output and greatly reduce the need for constant prompt engineering.
Longer term, I’m convinced that the other new features announced on Nov. 6th, including Function Calling and Tools, will open up a whole new range of possibilities in my recipe ingestion pipeline. Check out Max Woolf’s post Pushing ChatGPT’s Structured Data Support To Its Limits to get a feel for what’s possible with structured data, function calling, etc.
My interim solution is to use both models:
- Use the limited Chat Completions API paired with the
gpt-4-vision-previewmodel to extract the recipe content - Feed that content (text!) into the more powerful pairing of Chat Completions API paired with the
gpt-4-turbo-previewmodel new API so I can take advantage of JSON Mode
I know, though, that I’m discarding a tremendous store of context by bridging between models using only text. As soon as OpenAI fully integrates Vision into its updated and new APIs, I’ll rid myself of this compromise and start looking at how I might apply function calling, tools, etc.
Enrichment
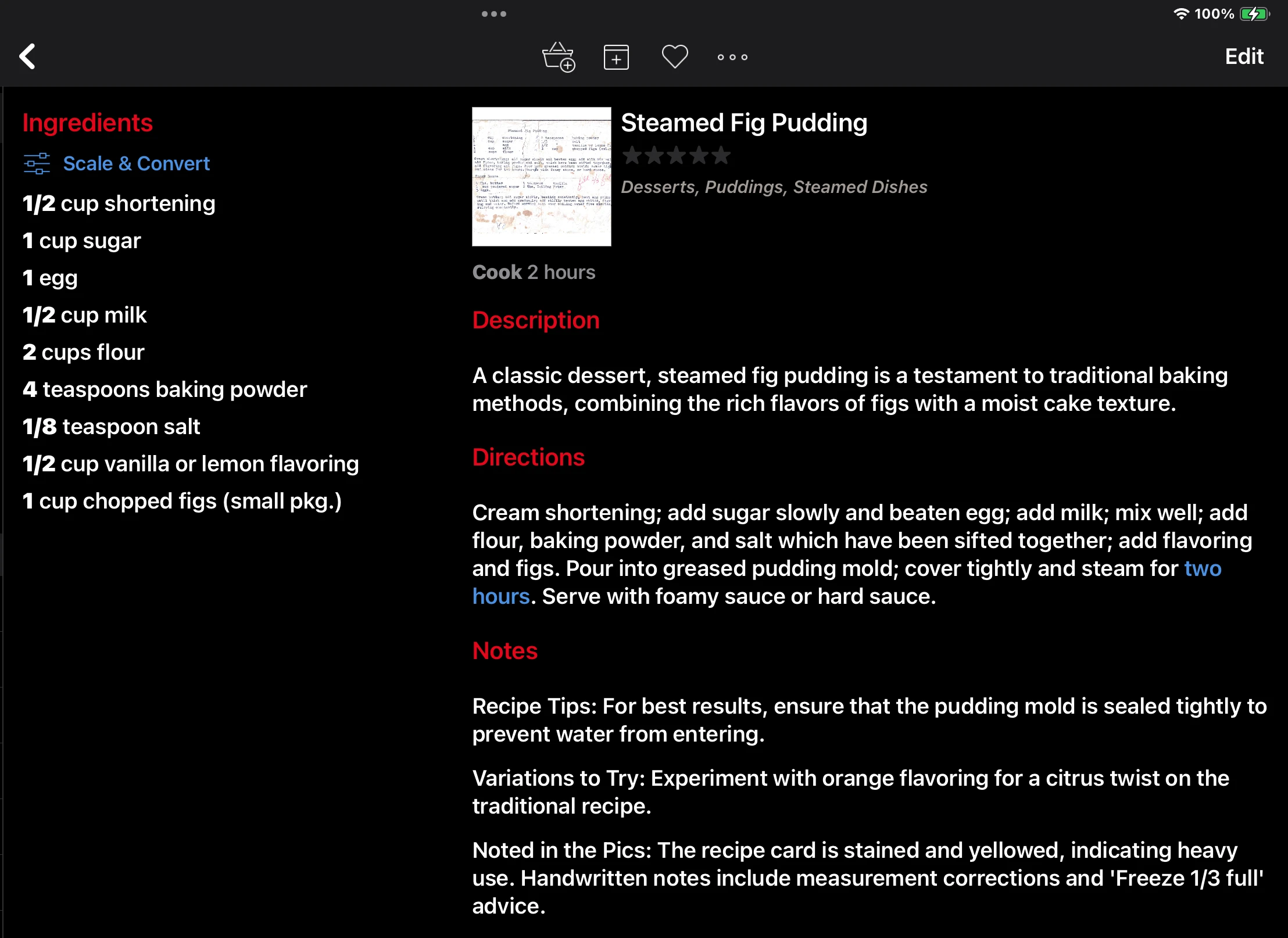
You may have noticed that the final recipes showing up in Paprika have been significantly enriched. Take this before-and-after example (click image to zoom):

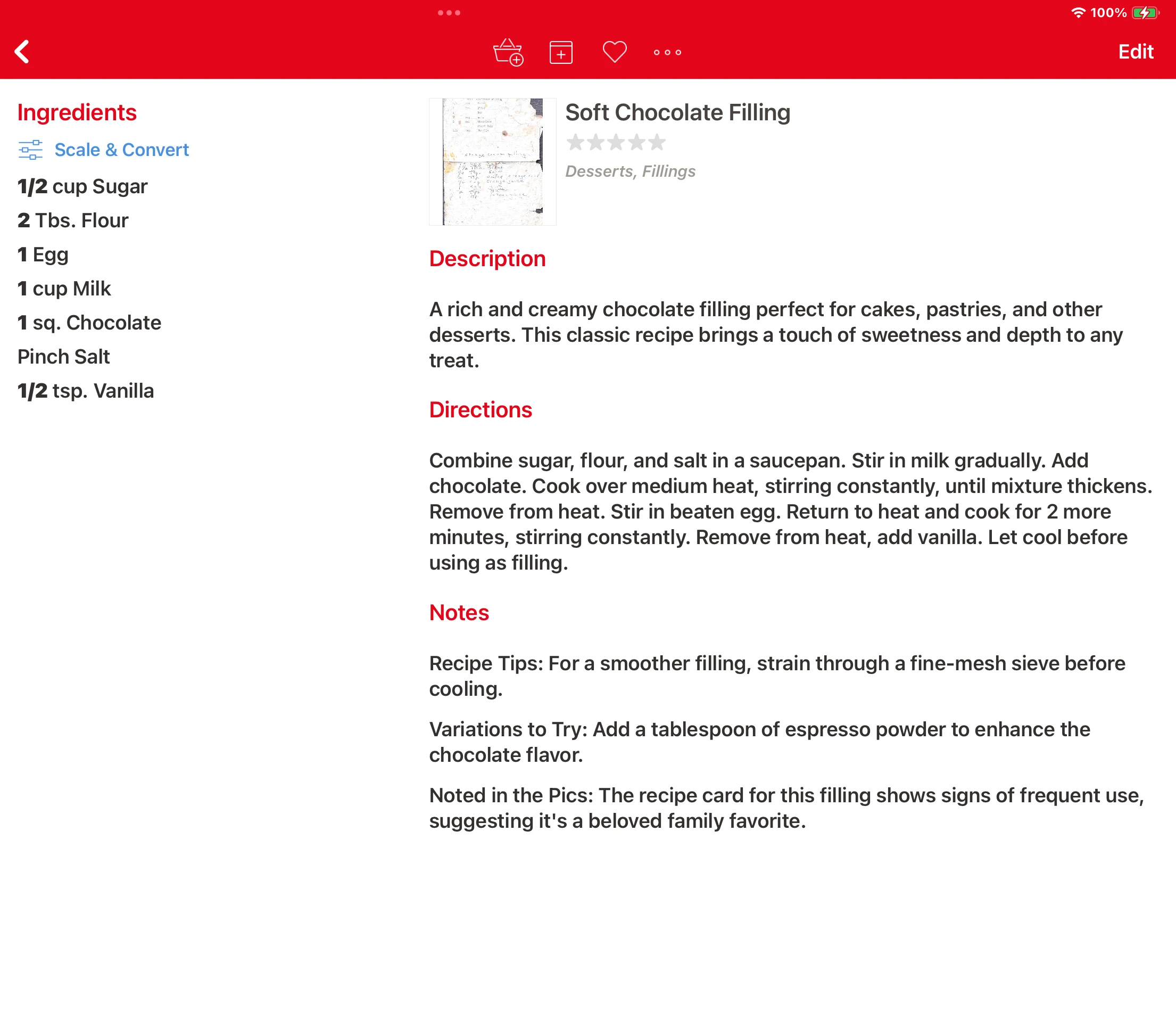

This a tour de force of GPT-4V’s content extraction: it correctly parses both typewritten and handwritten content, and likewise recognizes that these are two separate recipes. I end up with JSON content ready to feed into Paprika.
But look closer—the original image doesn’t have any directions—how did that get into Paprika? And what’s this Description section? And those notes? That’s enrichment in action.
Whimsical enrichment
If you’ve spent time with ChatGPT, you know that it loves to be creative, to cheerfully, energetically overdeliver and over-explain. Early in my process here, back when I was doing everything through the chat interface, I decided to let the GPT use its imagination in the Notes section:
Within the notes section of this recipe, please add a paragraph “Recipe History:” and invent a mythical history of the origin of the recipe, inventing family members like great aunt Dora. Regenerate the recipe yaml with this added.
The GPT came back with:
This cherished recipe dates back to the early 20th century and was a specialty of Great Aunt Dora, a renowned baker in her small town. Legend has it that Dora won the heart of her town with this cake at the annual winter fair. She ingeniously added crushed peppermint candies from her childhood candy jar, which became her secret signature. The recipe was passed down with love through generations, each adding their touch but always keeping Dora’s spirited invention alive.
I provided some real historical data to help ChatGPT create better stories
Our family has strong Irish and Scottish roots so as you do history on recipes, factor that in as you do histories. Family names include mcguire, clark, stewart. No need to redo the above.
Before long I was getting back pretty entertaining results
The recipe is believed to have been created by Seamus’s great-aunt, Eilidh McGuire Stewart, who was known in her village for her bountiful kitchen and her generous heart. Eilidh often baked this cake during the harvest season, and it became synonymous with the warmth of her home. Legend has it that Robert Burns himself enjoyed a slice of Eilidh’s cake during a visit, praising its rich flavor and the tender hands that made it.
Alas, the whimsical enrichment got old after a while and I ended up removing it from my instructions. But the idea that ChatGPT could enrich the recipes stuck with me and has been a focus my most recent work.
Useful enrichment
I’m currently focused on practical, useful enrichments only. So far here’s what seems to be working:
Category assignment
This is a slam-dunk win. Categories are a feature I never got around to using in Paprika, and GPT-4 is quite good at picking them.
Instructions
I actually don’t prompt GPT-4 to create these—in fact I prompt significantly for it not to add content unless instructed—but it decided on its own, correctly, that this would be a useful addition in the filling recipes above. I haven’t tried the instructions out yet, but superficially they appear plausible and this should be well within GPT-4’s capabilities.
Description
Here I’m prompting for a brief essence-of-the-recipe summary, another strong GPT-4 skill. I’m still working to avoid hyperbole that creeps in sometimes.
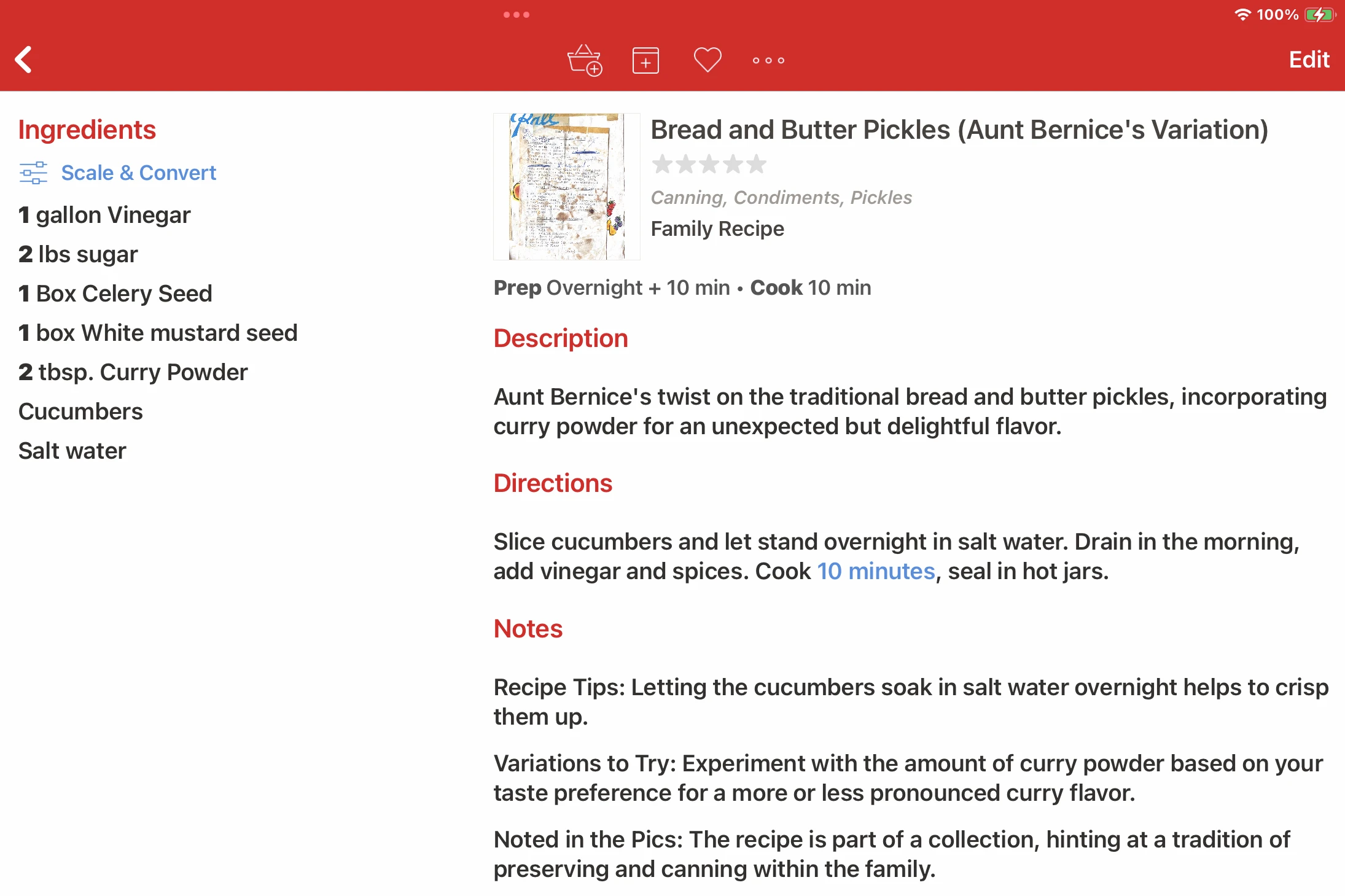
Recipe Tips
This gives GPT-4 a chance to provide helpful tips, and a lot of them do seem to be useful.
Variations to Try
GPT-4 has, what, 10 million recipes in its training data? 100 million? It’s pretty good at suggesting interesting variations. And none of the horrifying recipe mistakes that we used to see in GPT-3 days.
Noted in the Pics
In my first processing pass using the gpt-4-vision-preview model, besides extracting the core recipe data, I ask for a description of the physical properties of the recipe based on the images provided. Then in the second pass with the gpt-4-turbo-preview model, I ask GPT-4 to comment on notable physical aspects. This isn’t working well yet, and I’m sure the fact that I’m forced to use a text-only bridge between the Vision and Turbo models is reducing the value of this enrichment.
Prompt engineering
Oh, the prompting I have done. This project, which still supports both YAML and JSON output, contains a total of 4 active and 7 inactive prompts. Common categories of prompt engineering for this project:
- Structured output: Before JSON Mode, I did a lot of prompting to ensure the output was valid YAML or JSON.
- Shut up and stop making things up: ChatGPT just loves to be helpful and creative. I’m ok with that, carefully controlled, where enrichment is needed, but without lots of guidance, I was losing the original recipe content, and instead getting made-up facts, “family” and “heirloom” seeming to trigger the GPT into fantasy.
- Plain Old Prompt Engineering (POPE): A massive number of test-then-tweak-prompt iterations, just fine-tuning how I phrase what I want, tuning for better results.
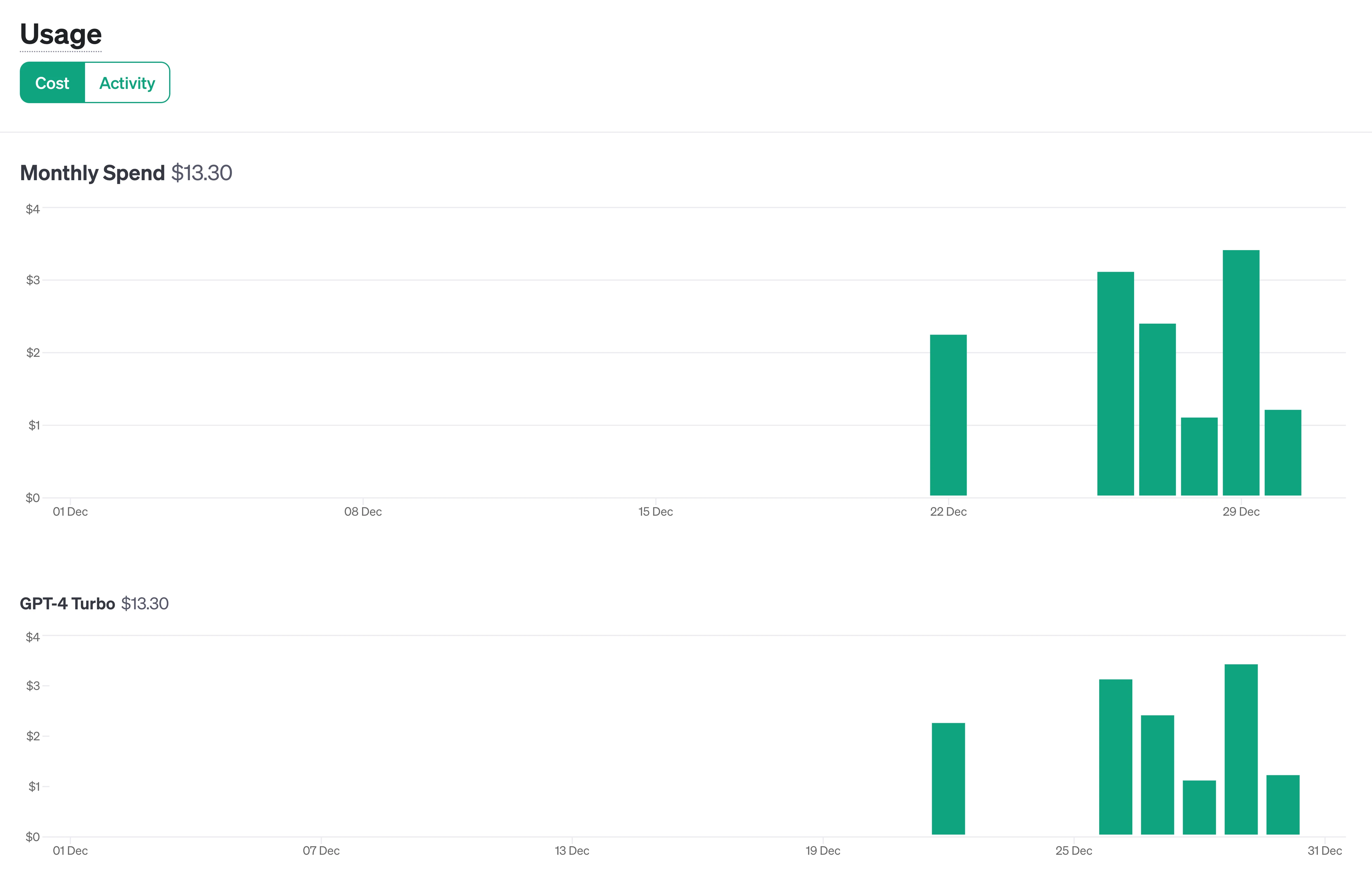
All of this testing came at a cost—the tall green bars show days where I was actively testing, with daily API charges approaching $4:
In summary
In the meantime, I’ve got a great way to preserving our heirloom family recipes while enjoying the benefits of a modern recipe app.