
I did a micro-post recently, MosaicML’s Open Source MPT-7B Model Writes an Epilogue to The Great Gatsby. I was a bit puzzled, though, that MPT-7B was showing up as current news, since its release happened in May. I started pulling on that thread and it unravelled interestingly.
MosaicML MPT-30B and MPT-7B Models
First off—it wasn’t the MPT-7B model that was the news over the past week, it was MPT-30B, announced June 22nd. 30 stands for 30 billion parameters, up from 7 billion in the MPT-7B model, with a corresponding increase in capabilities. This chart from MosaicML compares the two models’ capabilities:
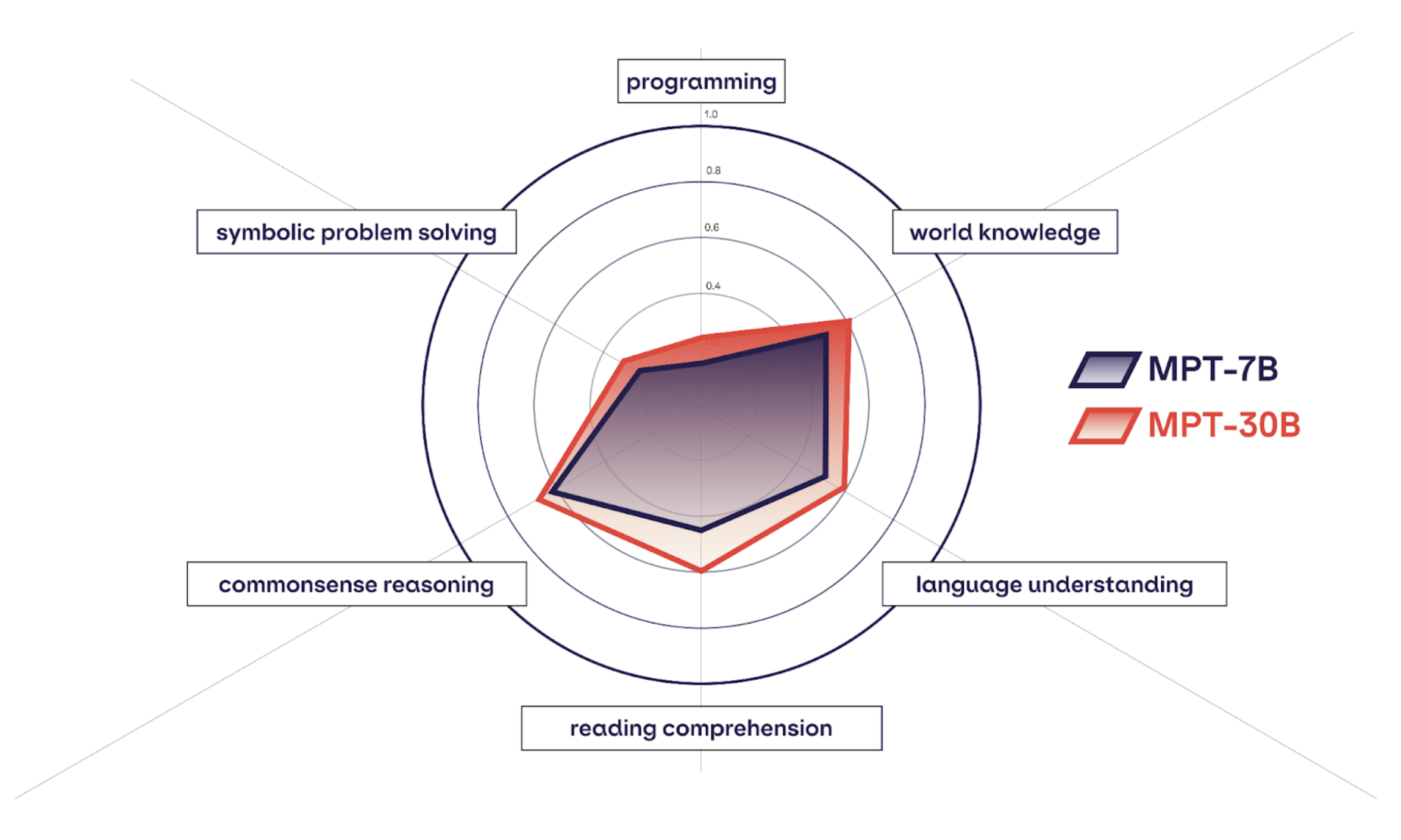
MPT-30B isn’t benchmarked completely on the LMSYS leaderboard, but 7B is there and competitive.
MosaicML’s Revenue Model Isn’t Models
Counterintuitively, although MPT-30B and 7B come from MosaicML, models aren’t the product, but rather enablers of Mosaic’s actual products—training and inference services. Here’s how Mosaic describes themselves on their homepage:
Generative AI for All
Easily train and deploy generative AI models on your data, in your secure environment.
Build your next model / transformation / disruption / innovation.
And when you look under the Products menu, you see:
Products / Training
Products / Inference
And finally, the language of Mosaic’s announcement post for MPT-30B is telling as well:
[Mosaic Logo] Foundation Series
MPT-30B
Open-source LLM.
Commercially licensed.
More Powerful.
MPT-30B and 7B are fully open source, ready-to use LLMs—pre-trained, fine-tunable, inference-ready, open training data, the works. They build upon the solid foundation of open source / open data projects that come out of a vibrant AI open source community.
Hmmm, this seems familiar, where have we heard about the power of the AI open source community recently … oh yes, the leaked Google document! Re-reading it again today, it’s as insightful as ever and worth another look.
The Leaked Google Memo
On May 4th, SemiAnalysis, a boutique semiconductor research and consulting firm, published a leaked internal document authored by a Google researcher. It has a powerful lead paragraph:
We Have No Moat
And neither does OpenAI
We’ve done a lot of looking over our shoulders at OpenAI. Who will cross the next milestone? What will the next move be?
But the uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch.
I’m talking, of course, about open source. Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today.
Both Google, and comparative upstart OpenAI, had strategies based around closed models, proprietary datasets, and eight-to-nine figure training investments. The during the madness of March, that entire strategy broke down.
The document continues:
Things we consider “major open problems” are solved and in people’s hands today. Just to name a few:
- LLMs on a Phone: People are running foundation models on a Pixel 6 at 5 tokens / sec.
- Scalable Personal AI: You can finetune a personalized AI on your laptop in an evening.
- Responsible Release: This one isn’t “solved” so much as “obviated”. There are entire websites full of art models with no restrictions whatsoever, and text is not far behind.
- Multimodality: The current multimodal ScienceQA SOTA was trained in an hour.
So during AI March Madness, the open source AI community solved four major problems that Google had on their “these will be tough” list.
Where does that leave Google?
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. This has profound implications for us:
-
We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google. We should prioritize enabling 3P integrations.
-
People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality. We should consider where our value add really is.
-
Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
This chart shows the accelerating pace of breakthroughs by the open source AI community:
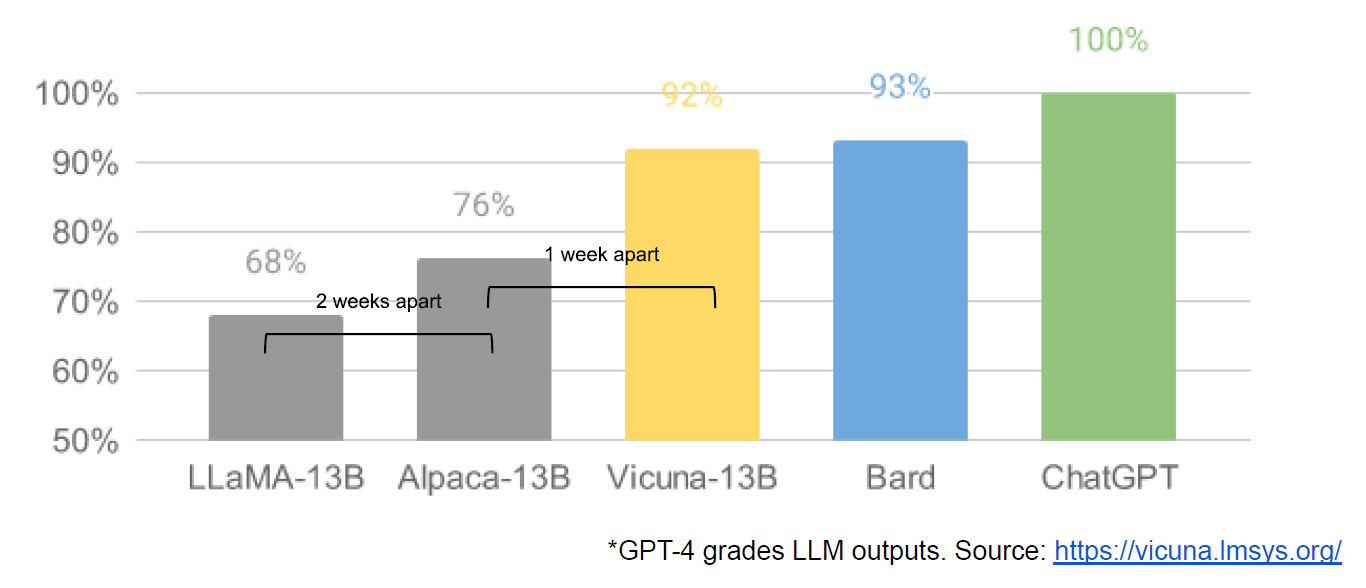
Repeat the phrase “doing things with $100 and 13B params that we struggle with at $10M and 540B” ten times fast—that’s the sound of the moat drying up and the alligators leaving town.

What Lit the Fuse?
This is a well-written document, top to bottom. Here’s its concise explanation of what happened to enable the open source AI acceleration:
What Happened
At the beginning of March the open source community got their hands on their first really capable foundation model, as Meta’s LLaMA was leaked to the public. It had no instruction or conversation tuning, and no RLHF. Nonetheless, the community immediately understood the significance of what they had been given.
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.
The details of “got their hands on” are critical. On March 10th, Meta did a limited release of their LLaMA model, to researchers only, and with non-commercial-use license. This in and of itself was a huge move, as no model of LLaMA’s scale and power had ever been released in its entirety, even to a limited researchers-only audience. But then, just a few days later, the same complete model was leaked publicly. So the entire AI open source community now had a complete large-scale model. Then followed the “tremendous outpouring of innovation.”
Coulda Shoulda
The document makes clear that Google coulda, shoulda known this was inevitable, once the open source community got total access to both code and model weights of a full-scale language model, because just six months earlier, a virtually identical emergence occurred in the image generation (art AI) space:
Why We Could Have Seen It Coming
In many ways, this shouldn’t be a surprise to anyone. The current renaissance in open source LLMs comes hot on the heels of a renaissance in image generation. The similarities are not lost on the community, with many calling this the “Stable Diffusion moment” for LLMs.
In both cases, low-cost public involvement was enabled by a vastly cheaper mechanism for fine tuning called low rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs). In both cases, access to a sufficiently high-quality model kicked off a flurry of ideas and iteration from individuals and institutions around the world. In both cases, this quickly outpaced the large players.
These contributions were pivotal in the image generation space, setting Stable Diffusion on a different path from Dall-E. Having an open model led to product integrations, marketplaces, user interfaces, and innovations that didn’t happen for Dall-E.
The effect was palpable: rapid domination in terms of cultural impact vs the OpenAI solution, which became increasingly irrelevant. Whether the same thing will happen for LLMs remains to be seen, but the broad structural elements are the same.
The rapid domination Google Trends chart cited above focuses on Google’s Dall-E being rapidly overtaken by upstart Stable Diffusion; but let’s add Midjourney to the chart for even more fun:
In the art AI space, Midjourney was the little guy’s little guy, and now they’re absolutely killing it.
Bringing it Back to MosaicML
There’s more to the leaked document, all of it good and worth re-reading, but I think we’ve pulled on the thread long enough and can return to where our story began with MosaicML. If Google, OpenAI, and other deeply-funded closed-AI players are at risk of having no moat, then MosaicML is one of a myriad of open-source-based entities whose business is keeping the AI world moat-free.
And look at the timeline of all of this:
- December 2020-ish: MosaicML formed (stealth)
- October 13, 2021: Mosaic comes out of stealth, with the mission: reduce the cost of training neural network models
- August 22nd 2022: “Stable Diffusion Moment” for art AIs
- October 18th 2022: Mosaic launches pillar one, their training service
- November 22nd 2022: OpenAI launches ChatGPT
- March 10th: Meta announces LLaMA and makes a limited release to researchers
- Mid-March: The entire LLaMA model complete with weights leaks publicly
- May 3rd: Mosaic launches pillar two, their inference service
- May 5th: Mosaic releases MPT-7B and strongly emphasizes open source and commercial-friendly licensing
- May 10th: the internal Google document leaks
- June 22nd: Mosaic releases MPT-30B
- June 26th: See below!
Late Breaking News (June 26th)
Here’s a fun chaser—news that happened as I was in the midst of writing this:
Databricks is acquiring MosaicML in a stock deal valued at $1.3 billion, a move intended to democratize AI. The deal, announced on June 26, includes retention packages, and all 62 of MosaicML’s employees are expected to stay. The transaction is slated to close in July. Neither Databricks nor MosaicML used an outside investment bank on the deal.
(ChatGPT summary, not an official release)
I have zero inside knowledge, but I’m willing to bet that MosaicML’s valuation took a giant hockey-stick leap thanks to the open source AI emergence of the past few months. That emergence, of course, was only the latest ratchet-up in a series of accelerations that began with the Stable Diffusion Moment and ChatGPT in summer to fall 2022.
In any case, congrats to the MosaicML and Databricks teams! Sally forth and bust some moats!
