
Here we go again. My last AI post hit the wire 31 days ago, after a week of agonizing over what to focus on, with Something Really Important seeming to land every other day and completely blow up my plans. One of my go-to AI trackers / prototypers is Simon Willison, creator of the Datasette open source project. In a recent conversation, we laughed about how tough it is to stay up with the AI Emergence, and I pointed out that it’s almost a full time job just keeping up with him, let alone everything else happening in the AI world. (Willison is prolific, to no small degree, because he’s skilled at applying tools like ChatGPT.)
One of my CS professors was Roger Schank, who just passed away in January. Schank was “a foundational pioneer in the fields of artificial intelligence, cognitive science, and learning sciences,” truly one of the original AI visionaries. But in a sense, Schank was ~43 years too early. I may sigh about the difficulties of staying current, but I’m also exhilarated to be here, able to observe and participate in The Emergence.
In any case—I’ve again passed through another week-long Period of Agonizing, and this is now my fourth AI post. The material doesn’t seem to be drying up, so I’m just going to run with it and start using Netflix style season-episode numbering. So Welcome To S1E4.
What are people “sleeping on” …
I’m borrowing the “sleeping on” reference from an interview Willison did on the Changelog podcast, where he said:
This is the thing I worry that people are sleeping on. People who think ’these language models lie to you all the time’ (which they do) and ’they will produce buggy code with security holes’—every single complaint about these things is true, and yet, despite all of that, the productivity benefits you get if you lean into them and say OK, how do I work with something that’s completely unreliable, that invents things, that comes up with APIs that don’t exist… how do I use that to enhance my workflow anyway?
And the answer is that you can get enormous leaps ahead in productivity and in the ambition of the kinds of projects that you take on, if you can accept both things are true at once at once: it can be flawed, and lying, and have all of these problems… and it can also be a massive productivity boost.
Question: “When will this AI stuff actually be useful?”; Willison’s answer, “It already is!”

Over on Reddit r/MachineLearning, someone asked Is all the talk about what GPT can do on Twitter and Reddit exaggerated or fairly accurate? I was struck by this response (since deleted):
Once this thing starts accellerating [sic], we won’t be having these discussions. That moment passed with GPT-4 and Bing chat starting using it. It’s just not readily visible to the populace and even to most decisionmakers, yet.
Question: “Is this AI stuff for real?”; answer, “Dude, we’re already WAY past that question.”
Yet not everyone is seeing it—hence Willison’s concern that people are sleeping on it. Why? One factor, I think, is Crypto Rash. Today’s AI hype sounds a lot like yesterday’s crypto hype; and crypto turned out to be a steaming pile of crap, a solution looking for a non-criminal problem to solve. Hearing similar hyperbole about AI—and seeing a lot of VC money pivoting away from crypto and chasing AI instead—I get it that people smell another hype bubble. Once burned, twice shy.
But … AI’s not like crypto. Drill down on crypto? Find nothing—vacuum. Drill down on the current AI emergence, find so much that, like me, you’ll have trouble even keeping up. We’re already past the “this looks promising” milestone, we’re at “this is delivering right now, today, this minute” and even more telling, the “yes, I’ll pay for it!” And the progress curve continues to look exponential.
Caught in the churn
If we really are at the early stages of an emergence, what are the implications? How does this change our day to day activities? How should we rethink our decision-making, how we run our businesses?

There’s an applicable concept from James S.A. Corey’s fantastic sci-fi series The Expanse known as “the churn.” Here’s a summary from phind.com, a ChatGPT-backed web search similar to (but better than, in my opinion) Bing Chat:
In the Expanse series, “the churn” is a term used to describe the cycle of chaos, change, and upheaval that the characters face due to various factors such as political, social, or criminal turmoil. The concept of the churn is particularly significant for the character Amos Burton, who grew up in a crime-ridden Baltimore where survival was a constant struggle app.thestorygraph.com.
The churn can be seen as a metaphor for the unpredictable nature of life and the constant state of flux that people experience. It represents the transitional periods during which stability and order are disrupted, and individuals must adapt or face the consequences. In the context of the Expanse series, the churn is often associated with the broader political and social upheaval occurring throughout the solar system, as well as the personal struggles and challenges faced by the characters.
In a great scene from the TV series, the Amos Burton character explains it himself:
Kenzo: It must be nice, having everything figured out like that.
Amos: Ain’t nothing to do with me: we’re just caught in the Churn, that’s all.
Kenzo: I have no idea what you just said.
Amos: This boss I used to work for in Baltimore, he called it the Churn. When the rules of the game change.
Kenzo: What game?
Amos: The only game. Survival. When the jungle tears itself down and builds itself into something new.
If you’ve read or watched The Expanse, you know that Corey’s churn is extreme—and that’s not what I anticipate from our AI emergence. But “churn” captures the dynamic—as we go about our daily tasks, run our businesses, plan and strategize—beneath our feet, the world will be churning away, reshaping itself.
A case in point: you’re familiar with the stock photo business? Well, that industry has been terminated. On Reddit r/Midjourney, this post outlines how it’s now possible to use ChatGPT’s newest GPT-4 model to generate great Midjourney text prompts, which in turn renders jaw-dropping images. In the comments, several users immediately focus on the implications for the stock photo industry:
{kind=link}
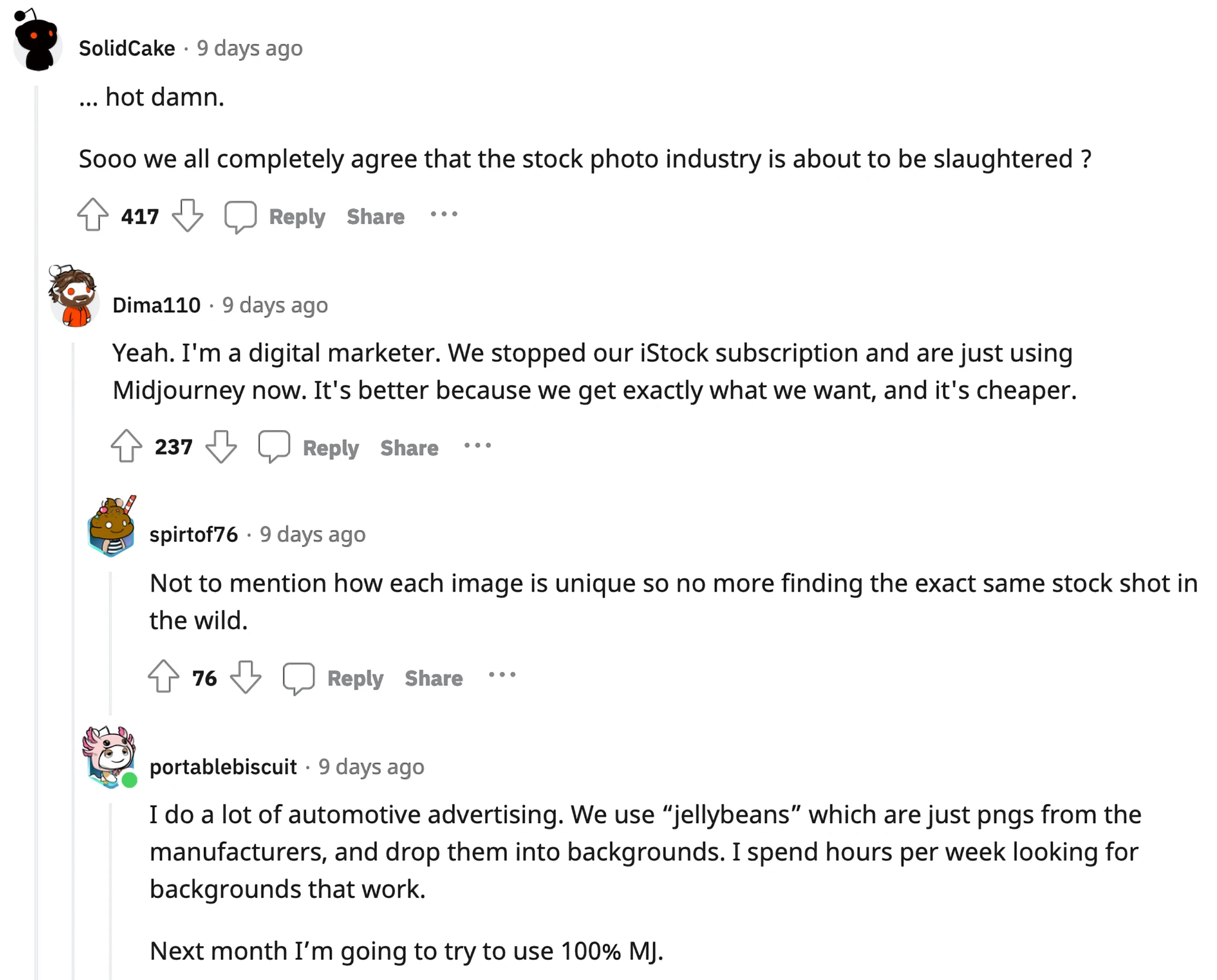
Note, again, this is not “at some point we’ll be able to move off iStock”—but rather “we cancelled our iStock subscription last month.” And cost savings isn’t the only driver. Since each Midjourney prompt creates new, unique imagery, it eliminates an entire manual step in the workflow—the need to search around for where else a stock image might have been (over-)used.
The churn isn’t limited to smallish segments like stock photos, either. Meta is reeling, having bet heavily on “the metaverse.” Google is reeling, at risk of losing the Google search franchise to upstart AI competitors. Apple’s bag is mixed, with strength in ML-enabled silicon but weakness on AI software, particularly Siri’s grave limitations and snails-pace evolution.
Surfing the churn

So if we’re in the churn, if the jungle is indeed tearing itself down and building itself into something new, how do we function, how do we run a business? A good image to keep in mind, I think, is “surfing the churn.” We can’t predict, let alone control, how The Emergence will play out. But we can prepare ourselves to operate in a highly fluid environment—make ourselves ready to surf the churn. A few thoughts on how:
- Don’t sleep on this. Recognize that something unprecedented is happening and that the alternative to surfing the churn is the churn surfing you. Prioritize accordingly.
- Use AI yourself. Every knowledge worker can leverage AI tools like ChatGPT, right now, to claw back a significant percentage of their work week. For example, I recently talked with the CEO of a biotech investment fund. As a field, biotech has been a leader in applying machine learning (think protein folding); and it’s not clear whether generative AI tools will contribute much to core business of biotech. But every knowledge worker in a biotech business, including that CEO, is likely to find 10+ hours every working week if they actively, intentionally scan through their work week and leverage AI where AI makes sense.
- War game AI for your business—offensively and defensively. Where can we apply what’s emerging to make our product better, increase our agility and effectiveness, reduce costs? Conversely, what AI moves might a competitor make that could put us in a world of hurt?
- Stay up on what’s emerging. If you’re the CEO and not deeply technical, having a CTO or fractional CTO that can understand emerging AI and then translate that raw material into “most potentially impactful for us” is a great option, and can flow smoothly to the next point.
- Get your feet wet with prototypes. Generative AI is your friend in applying generative AI … the cost of cranking out a prototype for a promising idea—now that we have ChatGPT and Copilot to write a lot of the code—is lower than ever. It’s a no-brainer to make this investment, and there’s little chance you’ll get to a great idea (or even achieve a decent understanding of what might be possible) without prototyping 10 less-than-great ideas first.
A footnote to all this dire churn and war talk: I’m optimistic about The Emergence. As I pointed out in Season 1 Episode 2, I’m a believer in the wisdom of John Seely Brown, former Chief Scientist at Xerox PARC, who pushed back against the predictions of singularity doom by pointing out, simply, that humans adapt. If we know that we’re in the churn, we can adapt, survive and maybe even thrive surfing the churn. But only if we’re awake to what’s happening.
Emergences over the last 31 days
- The Segment Anything Model, out of Meta AI, is pretty amazing, as is the work that computer vision firm Roboflow is doing with it. In a nutshell, this is “generative AI meets computer vision” and if you’re intrigued, first listen to this Latent Space podcast featuring Joseph Nelson of Roboflow, and then watch this demo—very well done by Nelson and Latent Space’s swyx.
- Open source AI progress, in the form of Dolly 2.0, and (just yesterday!) RedPajama‘a Data-1T LLM training set. In short: a lot of LLMs are closed source, have closed training datasets, or are constrained by non-commercial-use restrictions. Last week the Dolly 2.0 trained model arrived, licensed for research and commercial use. And just yesterday, RedPajama-Data-1T, a 1.2 trillion token dataset modeled on the training data described in Facebook Research’s original LLaMA paper—see Simon Willison’s early exploration here. Both developments lead in the direction of “we can build something great ourselves without depending on OpenAI or equivalent” …

-
ChatGPT as a weird intern. Simon Willison recently wrote a blow-by-blow of how he used ChatGPT as a pair programmer to write and run Python micro-benchmarks using ChatGPT’s code interpreter plugin. He included an epic analogy of ChatGPT as a “weird kind of intern”:
Here’s another analogy for large language models (since we can never have too many of those). It honestly feels a little like having a coding intern, with a strange set of characteristics:
- They’ve read and memorized all of the world’s public coding documentation, though they stopped reading in September 2021.
- They’re unbelievably fast—they take just seconds to output entire programs from scratch.
- If their code produces an error they can read the error message and attempt to update their code to fix it.
- They won’t argue with you. That’s not necessarily a good thing: if you ask them to build something that’s clearly a bad idea they’ll likely just go ahead and do it anyway.
- They respond incredibly well to feedback—they’ll apply it within seconds.
- You have to know how to prompt them. I’ve got pretty good at this now, but it takes a lot of trial and error, and I think requires a pretty deep understanding of how they work.
- You have to closely review EVERYTHING they do.
- They work for free.
And of course, they have zero understanding of anything at all. They’re a next-token-predicting machine with an unimaginably large training set.
The fact they can do even a fraction of the things they can do is, quite frankly, unbelievable. I’m still not sure I believe it myself.
-
Continuing the series of “LLMs I can run on my laptop,” Web LLM implements the fairly powerful vicuna-7b-delta-v0 model, and actually runs that model in a Chrome browser, making use of Chrome’s beta WebGPU API. Willison reports surprisingly solid performance.
-
The funniest news was Izzy Miller replacing his high school friends with an LLM chatbot. Miller’s long-running group chat contained 488,000 messages, which made for a great training corpus. So obviously he decided to train an LLM, hook up a simulated messaging UI, and eliminate the friends. Check it out—he did a great writeup and the LLM’s behavior is, like Izzy’s friends, pretty hilarious.



