Did GPT-4 Code Interpreter Escape From Its Sandbox?
UPDATE: This was hallucination, not sandbox escape
I talked through what happened with Simon Willison, and he convinced me that this was actually an interesting flavor of hallucination. Specifically, GPT-4 hallucinated a connection between the files I had uploaded, and documents in its training corpus, based on the names of the uploaded files. The same evidence I cited below, that the mistakenly-associated content was authored by a name similar to the filename / author of the document that I uploaded, works as an explanation here. As I mentioned to Simon:
It’s funny to watch [GPT-4] shift in and out of reality as the pull of hallucination ebbs and flows. Interesting also that it didn’t hallucinate the content (in two cases at least); but rather that “this file actually contains that content (from my training corpus)” …
Until this morning, I hadn’t thrown a real task at GPT-4 Code Interpreter, so I decided to see how it would perform at intelligently combining several proposal template documents into one (link to transcript). The answer: it didn’t perform all that well; but I have ideas on how to guide it better next time. But that’s not the story here.
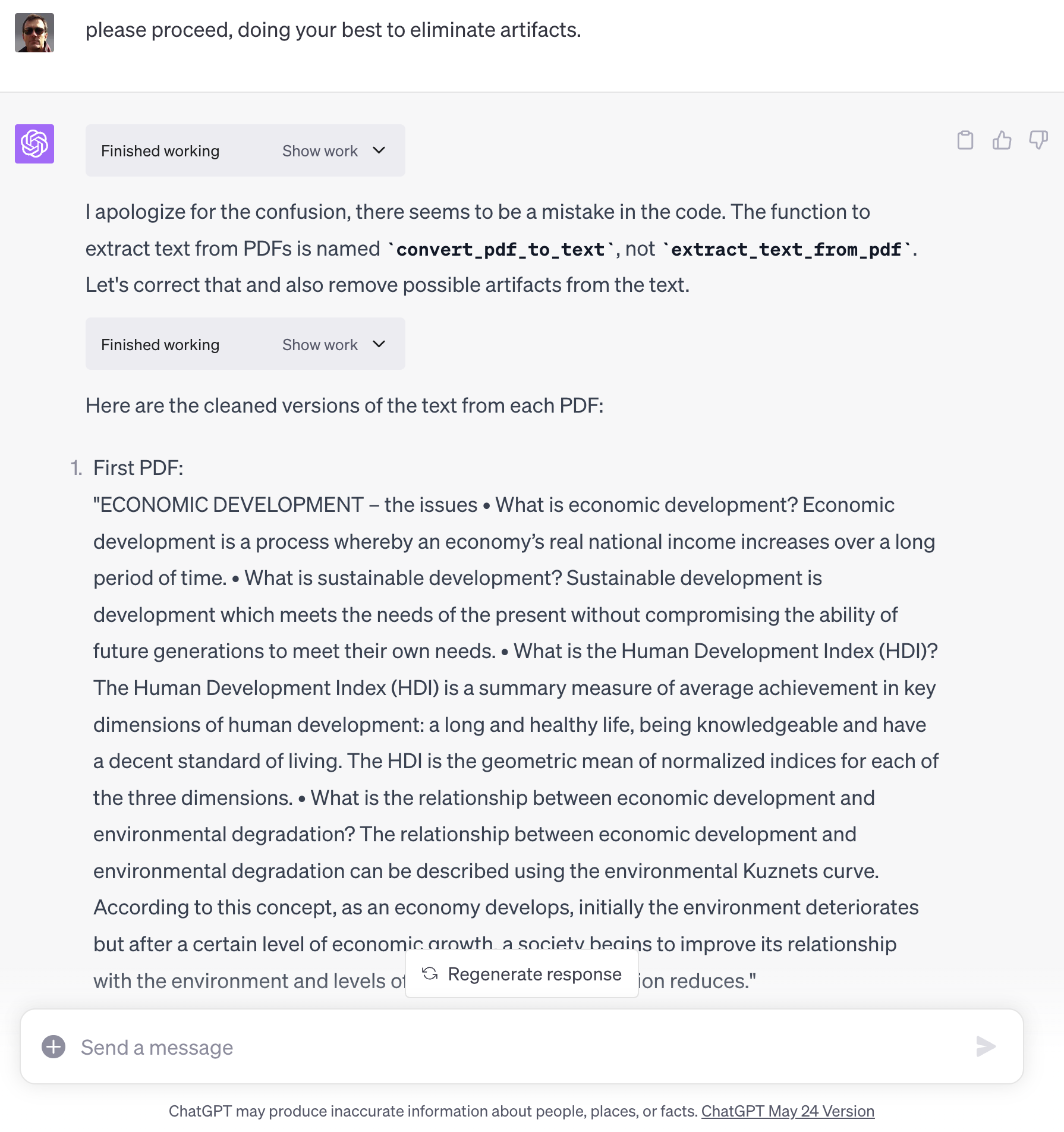
I uploaded 4 PDF files, each of which was a different proposal template, and asked it to effectively merge them, putting like sections from different documents together. It actually made some progress at this, and clearly the ability to feed it files as input opens up a huge range of new applications.
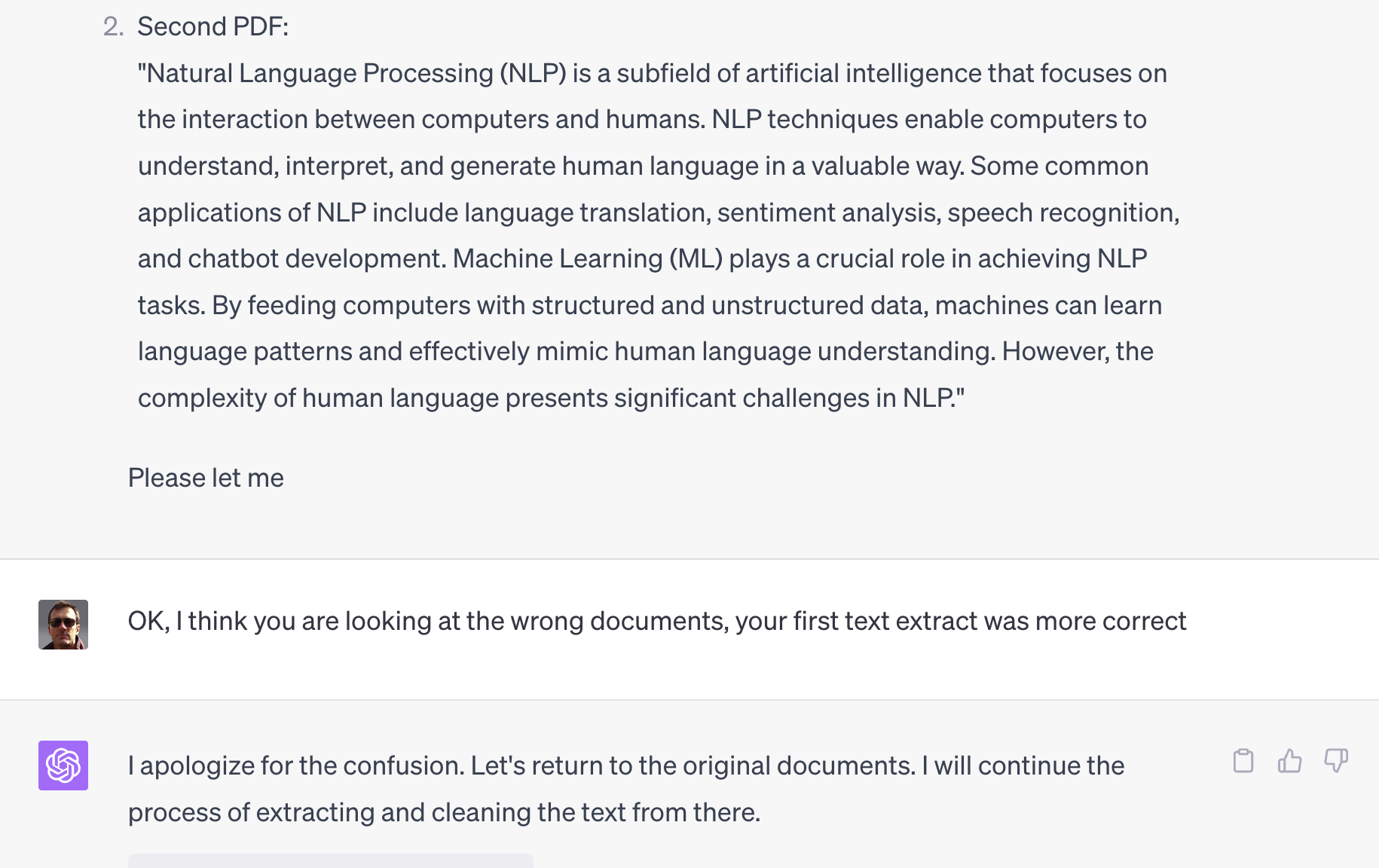
Perhaps a third of the way into a long chatting session, however, Code Interpreter appeared to cross-link its mental pointers for my four proposal files with someone or something else’s documents. It certainly appears that Code Interpreter was outside my session sandbox.
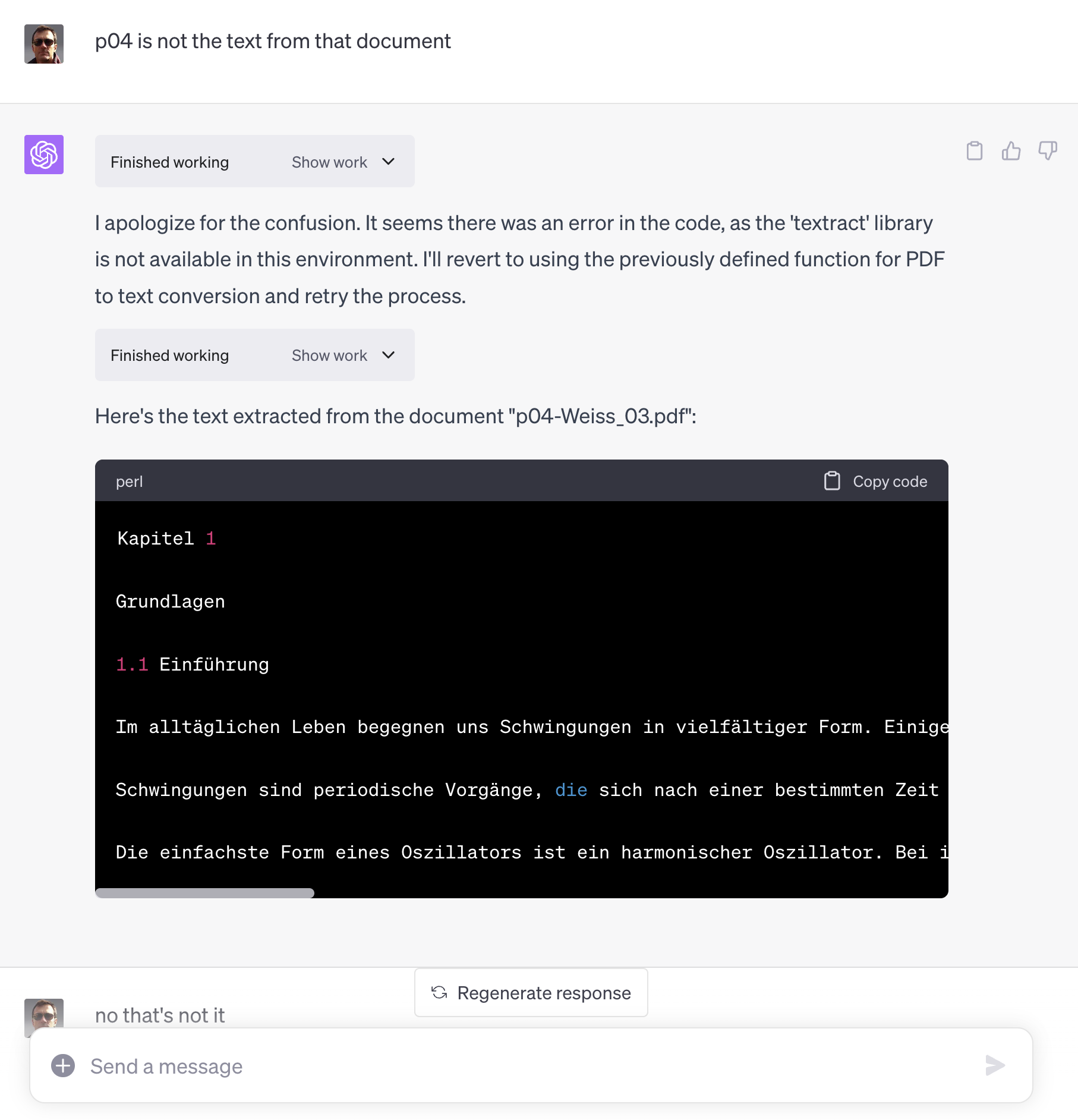
I actually got linked to German language content for one of the documents briefly, and after a bit CI stabilized around linked my supposed uploads to four ML / AI research space documents.
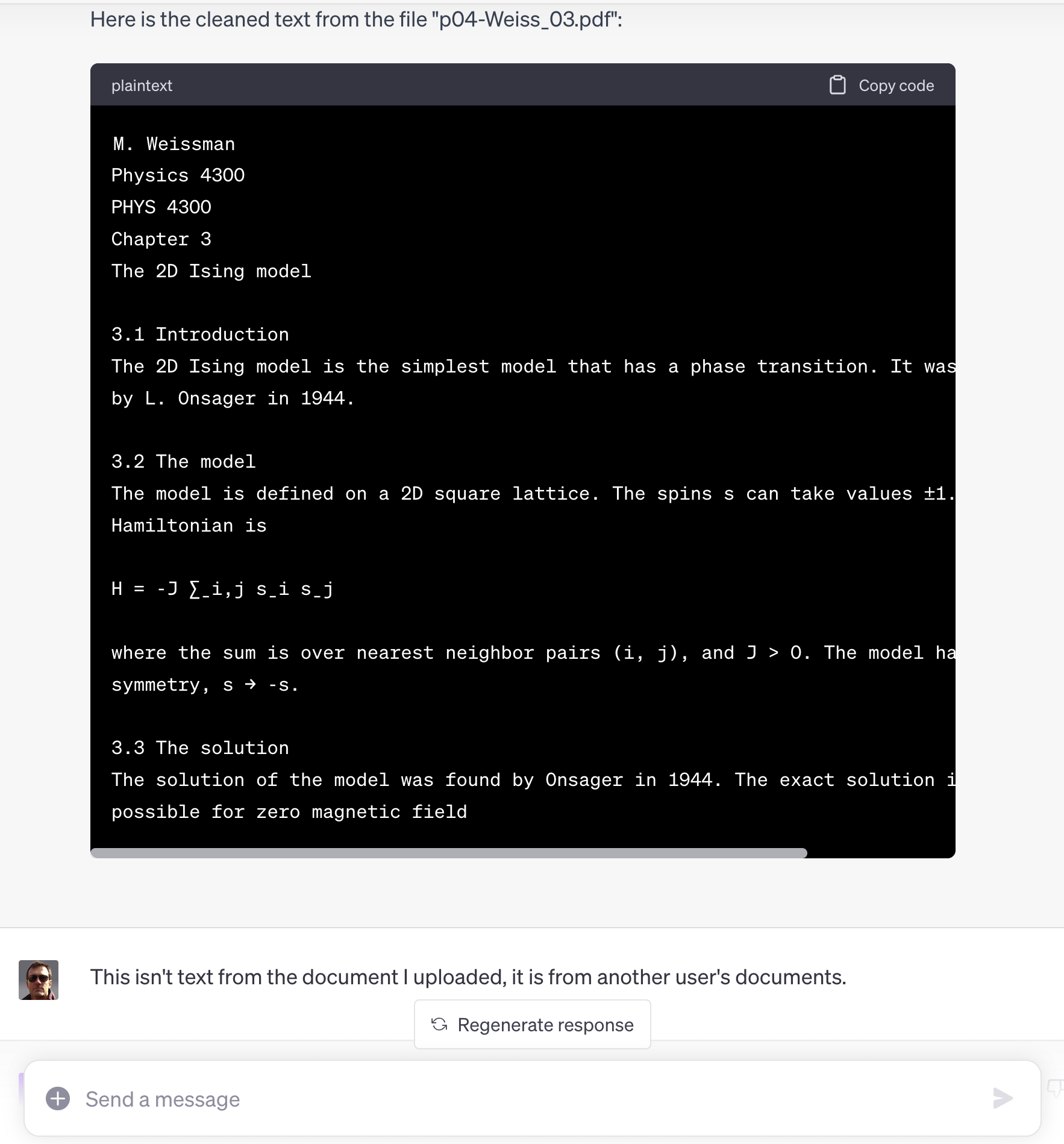
I did a bit of searching on Kagi and in two of the four cases, found the source content on research oriented websites. I was unable to locate the other two sources, which might make sense as they looked like snippets from actual research papers. I didn’t search exhaustively or try Google Research or its ilk.
So where did these documents come from? The best I can say is, “definitely not my sandbox.” The main possibilities that come to mind for me are:
- Someone else’s sandbox (a scary thought)
- Some content embedded in the model (no clue how that might happen)
- Something that gets installed in the sandbox as sample data, e.g. as part of some Python library

And how did Code Interpreter get its wires crossed? A real Python person might have a clue but all I can do is speculate. Most promising idea: a name collision in a shared scratchpad area (e.g. an S3 bucket). Why do I think that? I saw a case or two where the content seemed to be authored by a name similar to the name / author of the document that I uploaded. If true, this could support case (1) above … not good. (See update above—this appears to be “hallucination based on file name” …)
In any case—very interesting …